上篇已经聊过 1.24 前的 map,这篇让我们看看 1.24 之后的实现 —— 瑞士表(SwissTable)
1 引
在有一次面试的时候,面试官问了我一个问题,这个问题在我学习 SwissTable 的时候意识到是同一个问题。问题如下:
现在有一百万条数据要做处理,还有一个足够大的内存能放下这一百条数据,现在假设这个数据有两种组织方式,一种是链表,另一种是数组,请问哪一种处理起来效率会更高?
这个问题我当时是这么回答的(当然这里语言组织的比当时好很多^-^):数组处理效率更高,因为 cpu 把数据从内存读到寄存器的时候,不是一次拿一条数据,而是一次拿一块连续的内存放进 cache。此时如果是链表的情况,链表两个节点在内存空间中地址不连续,就会导致我一次拿的内存可能不会覆盖到下一个节点,那么拿下一个节点的时候,又需要访问,带来了额外开销。而数组不一样,连续的内存让他有了很好的空间局部性,拿一块内存,那下一次访问的数据也大概率会在 cache 中找到,减少了访存的次数,从而提高了性能。
1.1 拉链法的性能瓶颈
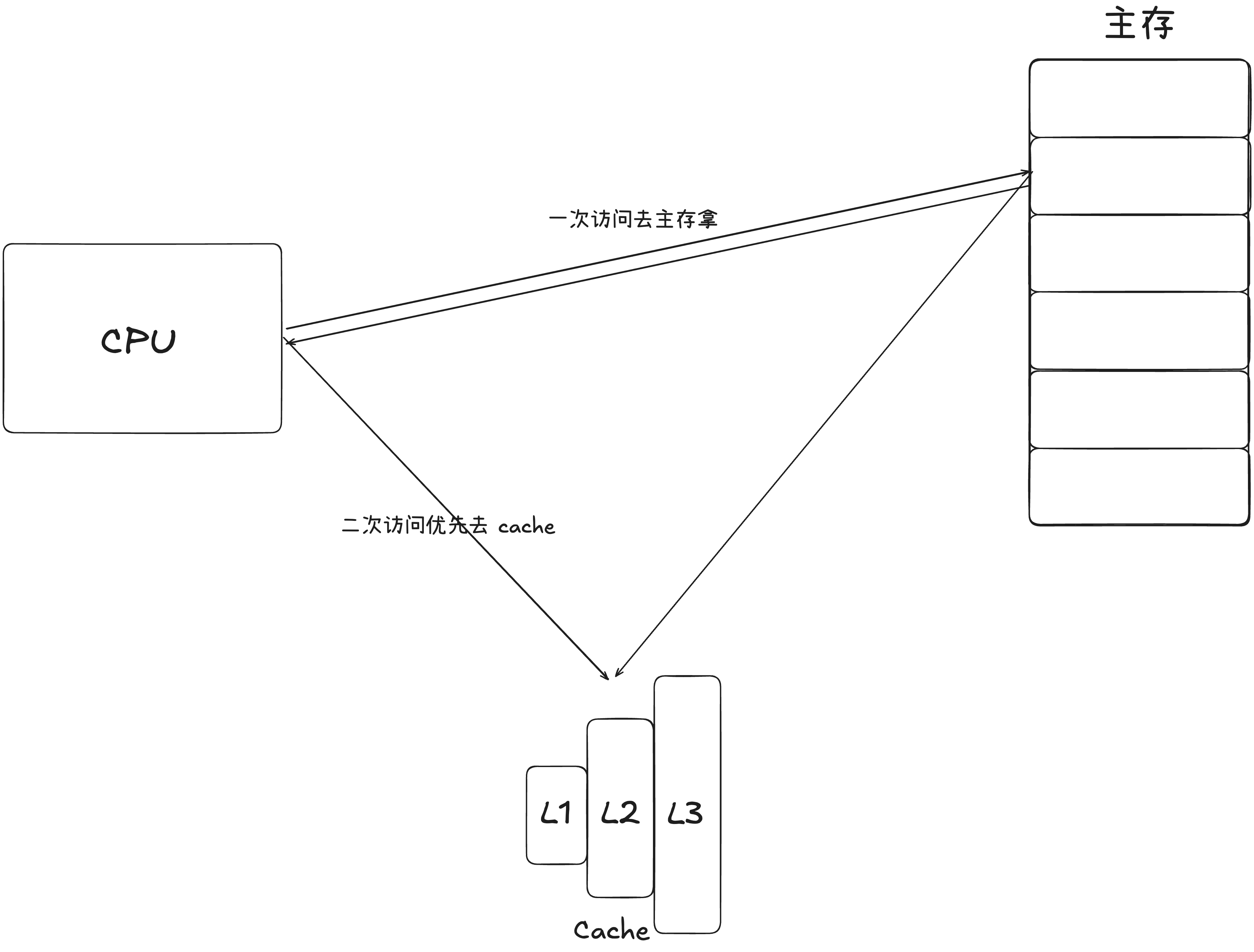 从上面的这个引子也就知道了,拉链法指针地址的离散型,是对 Cache 不友好的,按照现代计算机的设计来看,离 CPU 越远,获取数据的成本就越高。换言之,我们希望有一种方式能尽可能让 Hash 表中的数据紧密起来,让 CPU 能一次访存,多次复用。
从上面的这个引子也就知道了,拉链法指针地址的离散型,是对 Cache 不友好的,按照现代计算机的设计来看,离 CPU 越远,获取数据的成本就越高。换言之,我们希望有一种方式能尽可能让 Hash 表中的数据紧密起来,让 CPU 能一次访存,多次复用。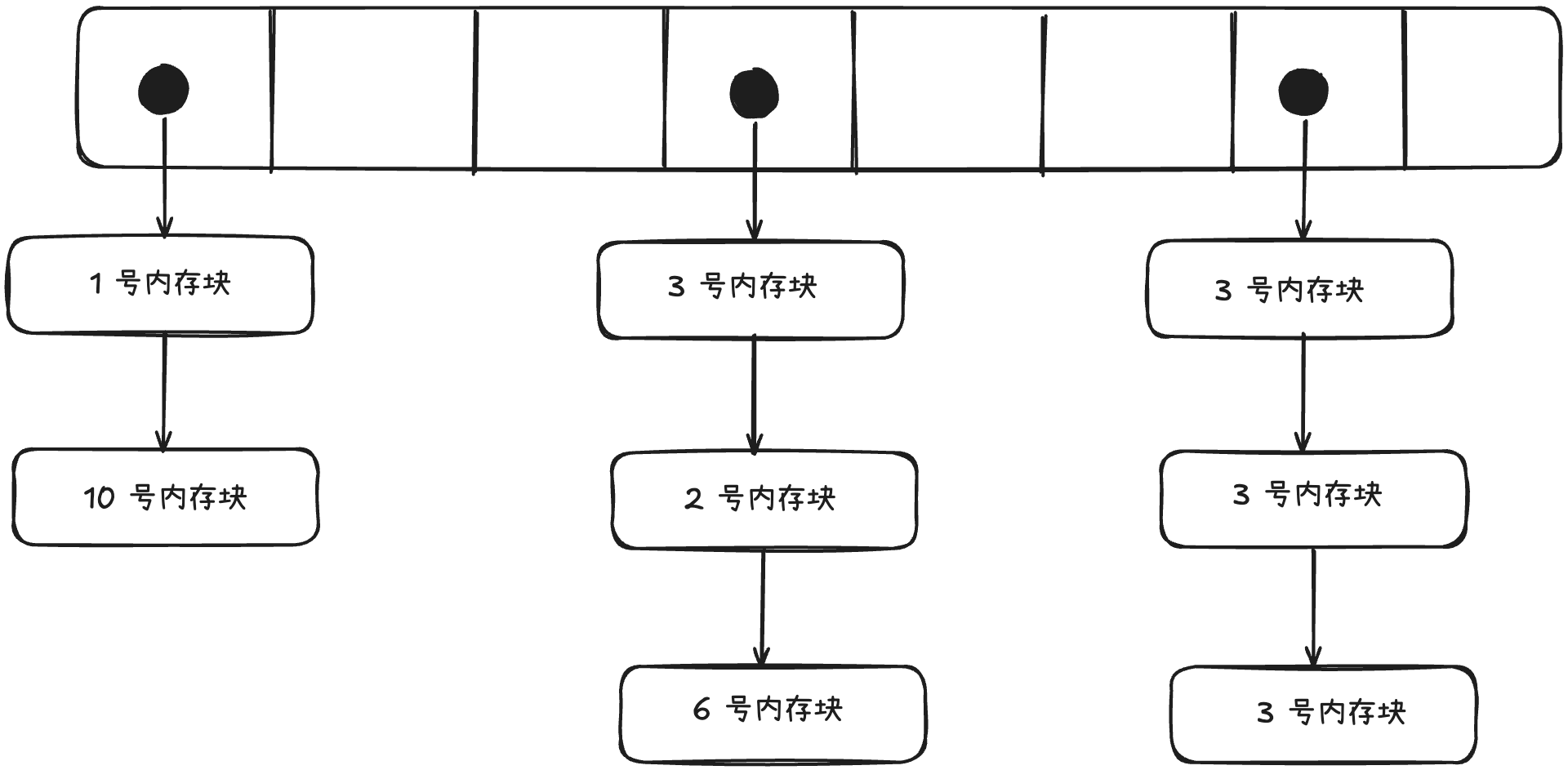 回到解决 Hash 冲突问题本身,除了拉链法,还有一种就是线性探测法。线性探测法是在 Hash 碰撞的时候,向后找位置,找到第一个可以放下该元素的槽(slot),接着插入,如果直到链表查完都没有 slot 可用,就触发扩容。查询的时候,会从 Hash 的起始 slot 往后查,直到查到元素或者查到空 slot 或者查完整个表,结束查询。 线性探测法的链表会呈现出如下的形式。(忘记画slot的状态的,简单看看~)
回到解决 Hash 冲突问题本身,除了拉链法,还有一种就是线性探测法。线性探测法是在 Hash 碰撞的时候,向后找位置,找到第一个可以放下该元素的槽(slot),接着插入,如果直到链表查完都没有 slot 可用,就触发扩容。查询的时候,会从 Hash 的起始 slot 往后查,直到查到元素或者查到空 slot 或者查完整个表,结束查询。 线性探测法的链表会呈现出如下的形式。(忘记画slot的状态的,简单看看~)
 可以看出来如果是线性探测法的 Hash 表,只需要一个数组就能承担责任,而数组是内存连续的地址,妥妥的cache friendly。而且实现起来也相对简单,每个位置只需要存储 kv 对以及当前 slot 的状态(是空还是已删除还是有数据)。固然缓存友好,但是线性探测法的缺点在哪里?
可以看出来如果是线性探测法的 Hash 表,只需要一个数组就能承担责任,而数组是内存连续的地址,妥妥的cache friendly。而且实现起来也相对简单,每个位置只需要存储 kv 对以及当前 slot 的状态(是空还是已删除还是有数据)。固然缓存友好,但是线性探测法的缺点在哪里?
- 冲突的 Key 总归是要存储起来的,而其存储会占用其他的 Hash 槽,会导致其扩容频率高于拉链法。
- 查找过程有大概率会退化到
O(n)的时间复杂度,而且没法进行像 Java 中的 HashMap 那样将链表转化为红黑树的优化。
1.2 单指令流多数据流(SIMD)
先上结论:SIMD 在 SwissTable 中的应用很大的提高了 Hash 对比的效率。
在具体展开讲 SwissTable 之前,先来回顾一下 SIMD,也就是一条指令操作多个数据。连续内存带来的优势会被 SIMD 进一步放大。与 SIMD 对应的是 SISD,也就是单指令流多数据流。
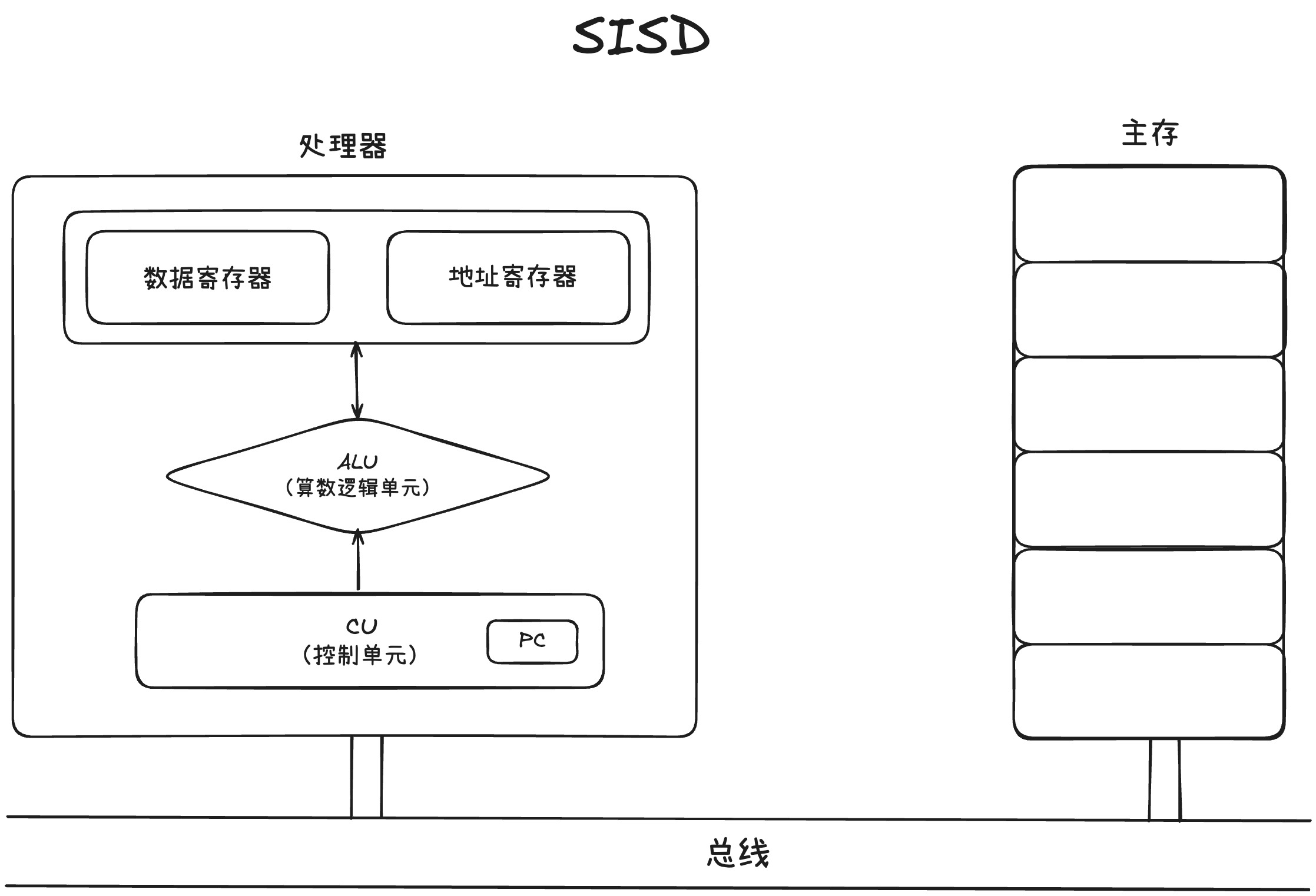 单指令流多数据流硬件层面的限制,导致了一条指令只能操作一个数据,无法实现数据并行。
单指令流多数据流硬件层面的限制,导致了一条指令只能操作一个数据,无法实现数据并行。
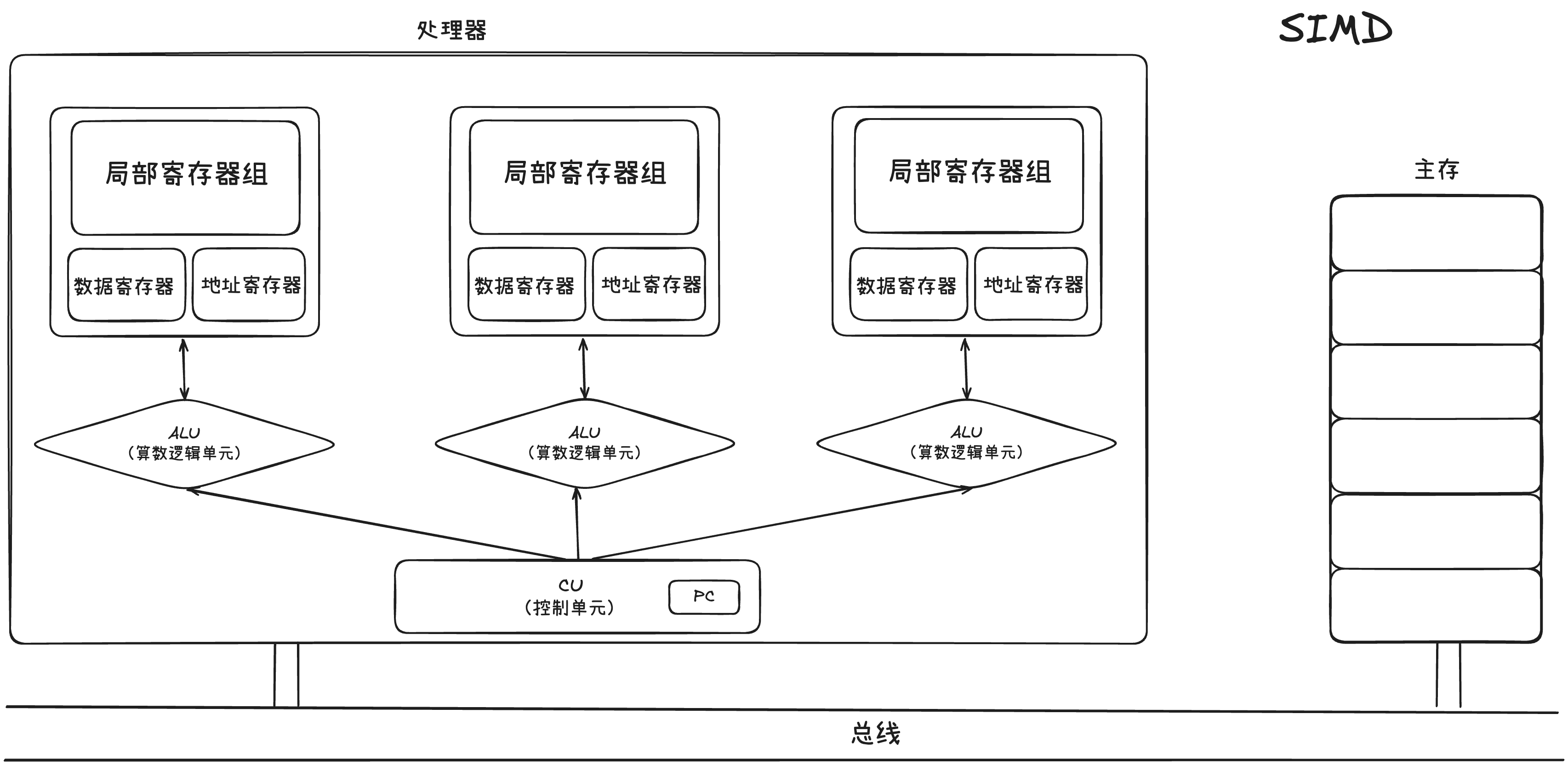 而在 SIMD 中,每个ALU 前面都有自己独立的局部寄存器组,当 CU 会把指令下发给所有 ALU,然后 ALU 会从自己的局部寄存器组中获取不同的数据,然后进行一样的操作。举个例子:
而在 SIMD 中,每个ALU 前面都有自己独立的局部寄存器组,当 CU 会把指令下发给所有 ALU,然后 ALU 会从自己的局部寄存器组中获取不同的数据,然后进行一样的操作。举个例子:
A = [1, 2, 3, 4],B = [4, 3, 2, 1] 求 A 中元素和 B 中元素对应位置相加。
首先在访存的时候,会分别将 A 和 B 的数据按地址分为四块,放入四个 ALU 中的局部寄存器,然后,CU 发 ADD 指令给每个 ALU,ALU 会从读出局部寄存器的值,然后独立的进行操作,从而实现单指令流多数据流。
这里就看出了 SIMD 的对数据的基本要求:
- 指令操作的数据需要在内存中连续,这样 CPU 在访存的时候,才能一次拿出来,并且分块
- 各 ALU 之间操作的数据不能有重叠,且数据的起始地址要对齐到寄存器宽度的整数倍
- 所有参与 SIMD 的元素必须是相同类型
- 所有元素执行完全相同的运算逻辑
2 SwissTable(折中的取舍)
在 Go 1.24 之后,底层 map 的实现改为了使用线性探测法的一种数据结构 —— 瑞士表(SwissTable)。
- SwissTable 是在 2017 年的 cppcon 上谷歌工程师正式宣布推出的。Google 的工程师在演讲上表示说在 Google 的集群上,仅 Hash 表这一个数据结构,就占用了约 1 % 的 CPU 和约 4% 的内存,这还只是针对 C++ 的情况,会议视频链接放在文章末尾。
- 推动 Go 改用 SwissTable 的 issue 实际上也是由字节团队提出的,他们表示在字节,Go 服务大约消耗了 4% CPU 用于 map。其次,
mapassign()和mapaccess()的比重是 1:1,也就是插入和获取性能同样重要,而 Abseil 和 Rust 早就引入了 SwissTable 作为 map 的实现,所以希望Go 也能改用 SwissTable(毕竟字节是 Go 大户),并给出了 SwissTable 的 Go 的实现。 上面两个大规模集群的例子中,1% 的 CPU 优化可能带来的是节省上万台服务器,而 1% 的内存优化,带来的可能是数 TB 的 RAM 节省。所以为什么 SwissTable 能有这样的性能?让我们往下看看。
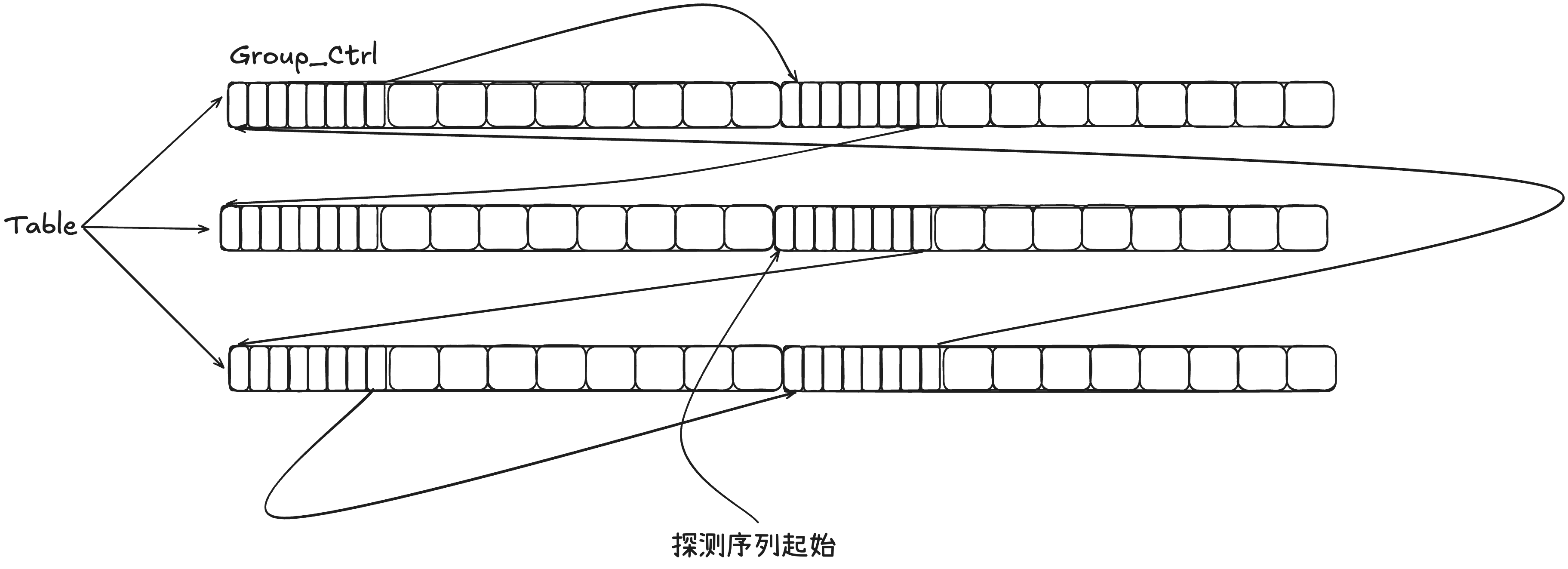
2.1 SwissTable 的结构
从内存布局上来看,SwissTable 长下面这样:(这个是一般的 SwissTable ,Go 的实现略微有一些差异,但基本上是没区别的)
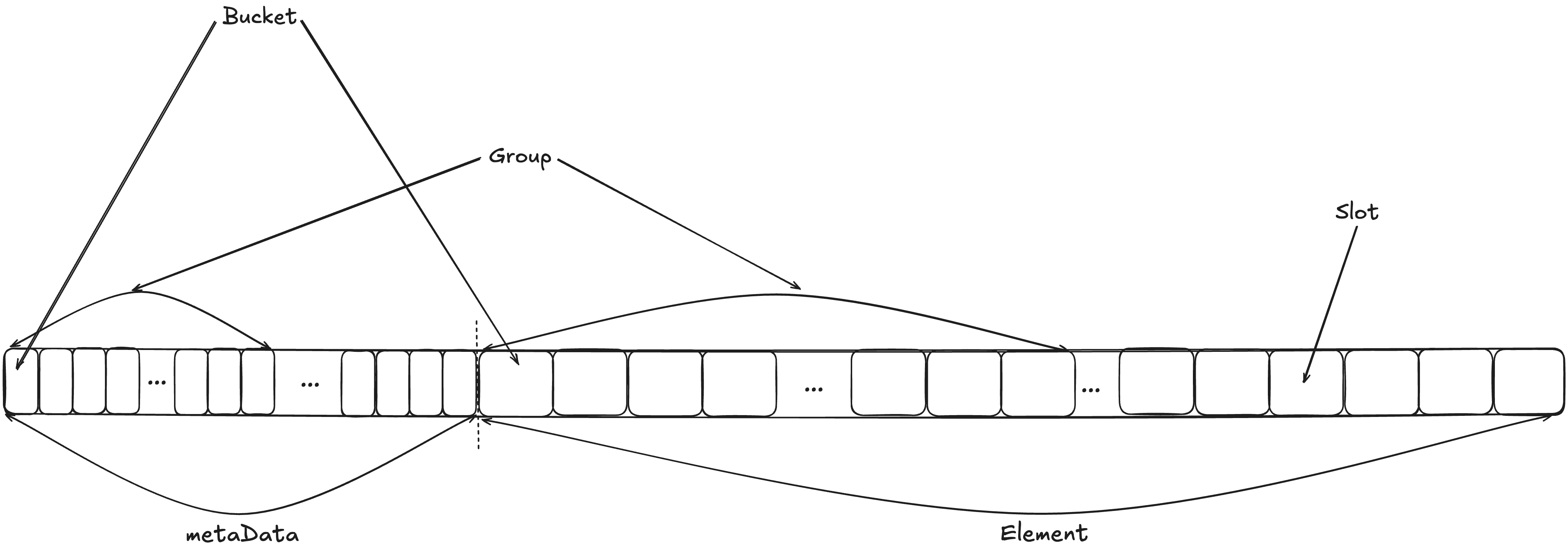 (虽然有点乱,但是有点乱^ _ ^)把上面这一整块看成一块连续的内存空间就行
(虽然有点乱,但是有点乱^ _ ^)把上面这一整块看成一块连续的内存空间就行
Bucket:一个 Bucket 用来存储和标识一个数据,Bucket 由一个 8 位的元数据 + 一个 Slot 组成。其中,Slot 是真正存储 KV 的地方,而 Metadata 是一个 1 字节的信息,其中高位 1 bit 是用来标识当前这个 Slot 的状态的,低 7 bit 是Slot 中存储的 key 经过 hash 计算后的低 7 位。
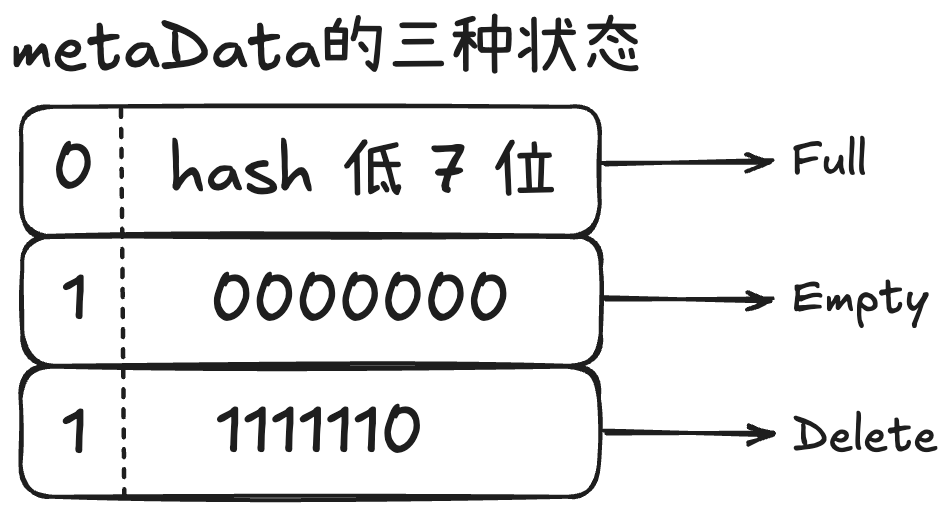 Group:一个 Group 包含了 16 个 metaData 以及 16 个对应的 slot。(这里16 个 solt 是可以变化的,因为在不同平台,SIMD 支持的并行数据流数据不一样,按照对应平台来)
Group:一个 Group 包含了 16 个 metaData 以及 16 个对应的 slot。(这里16 个 solt 是可以变化的,因为在不同平台,SIMD 支持的并行数据流数据不一样,按照对应平台来)
2.2.1 SwissTable 的搜索
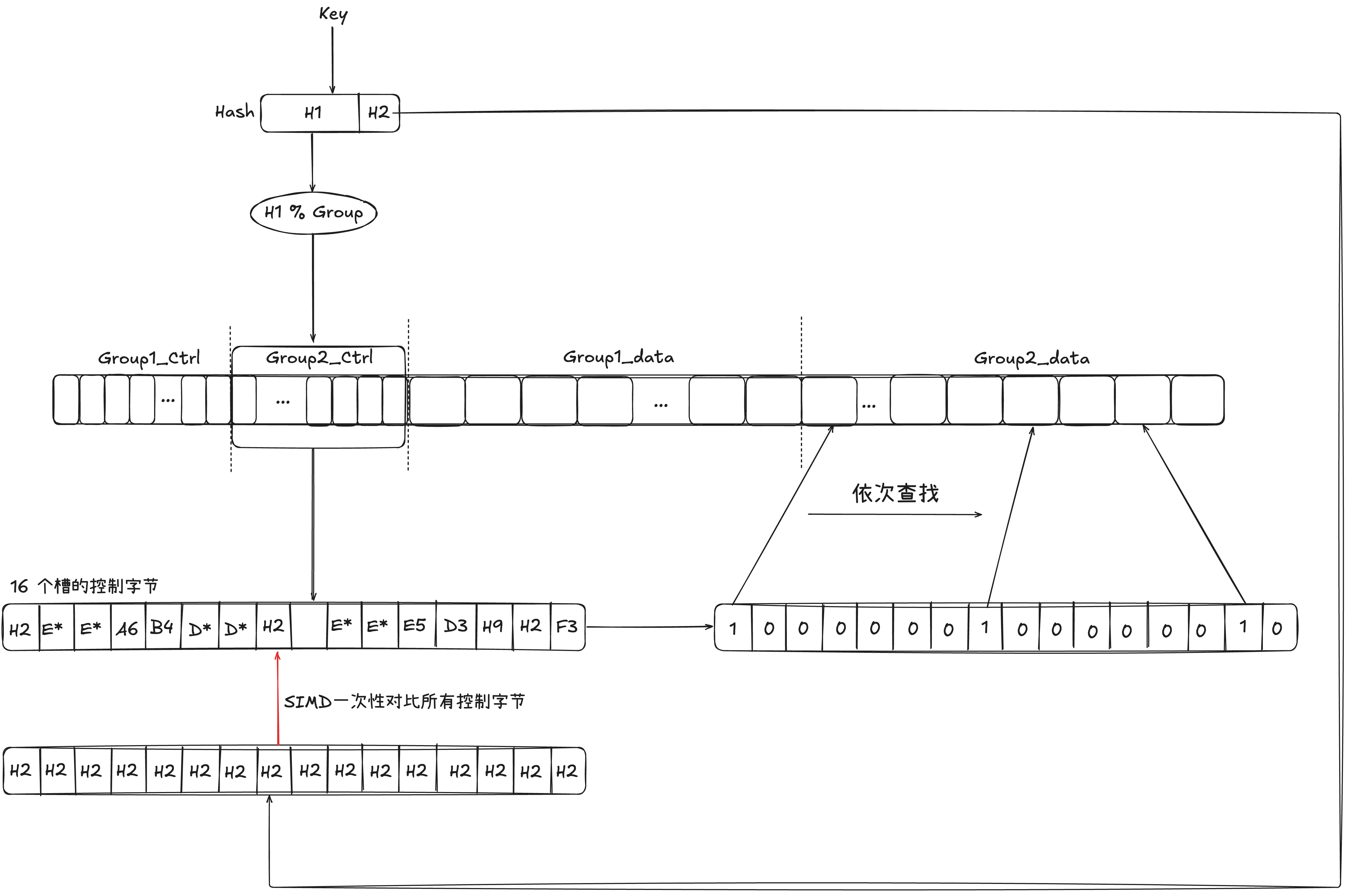
- 首先,key 经过 hash 函数会计算出一个 64 位(不同实现方案会有差异)的 hash 值,hash 值会被分为 h1(高 57 位) 和 h2(低 7 位)。
- 接着会使用 h1 对 Group 数取模,进而定位到具体的组(代表从这组还是搜索)
- 接着拿出该 Group 对应的控制字节(一般一组是 8 个或 16 个 slot,对应 8个或 16 个控制字节)与 H2 做对比,这里才用并行的方式,提高效率
- 对比成功的 Slot 则代表可能与该 Key 一致,需要进一步比对该 Slot 中的 Key 是否与目标 Key一致,一致则返回,结束搜索;否则跳过该 Solt,直到该 Group 搜索完。在搜索过程中,如果遇到一个 Slot 状态为 Empty,则无需继续搜索下一个 Group。
- 如果一个 Group 搜完还没找到,则按序搜索下一个 Group,直到找到 Key 或全表搜完。 起始比较重要的操作就是 SwissTable 的查找和插入,具体的插入操作因为涉及到了 map 的扩容,所以在下面第三章结合 Go 的具体实现展开聊
到这里,我们可以观察一下,SwissTable 先是利用了一块完整的内存空间,进而提高了 Cache (热数据)的命中率;另一方面,利用 SIMD 一次性对比多个 Slot 相较于传统的线性探测法的实现,又提升的查找的速度。那么代价是什么呢?
- 对于内存的空间利用率远不如拉链法,拉链法能很好的利用内存中的碎片。
- 因为其要求一整张表在一片连续的内存空间中,在扩容的时候,需要 Get 一片更大的连续的空间,并且需要把原来的全部 kv 对 rehash 到新的表中。
- 实现的难度相较于拉链法更难,因为除了键值存储,还需要存储槽位的状态。 其实两种方法都各有好坏,需要按照具体场景具体分析。
3 Go 的 SwissTable 实现
3.1 Map 的结构
我们先来看关于 Go 的 map(就是 SwissTable,下面用 map 代替,不然太长了^ _ ^) 的三个重要承载 Map 数据结构。我们从内到外,有细到粗将 Map 分为三个结构,分别是 Group、Table 和 Map。一个 Map 中包含一个或多个 Table,一个 Table 包含多个 Group。
3.1.1 Group
首先是 groupReference 和 groupsReference,groupReference 指的是一个组,不同于 SwissTable 的一般实现,go 的实现是槽后面紧跟 slot;而 groupsReference 就是多个 groupReference,但是内存是一次性连续分配的,也就是说 groupsReference 开辟了一块完整的内存空间,里面有多个 groupReference。他们是 map 底层存储数据的地方。一个组内最多 8 个 Slot(后续会解释为什么只有 8 个 Slot,而不是16)。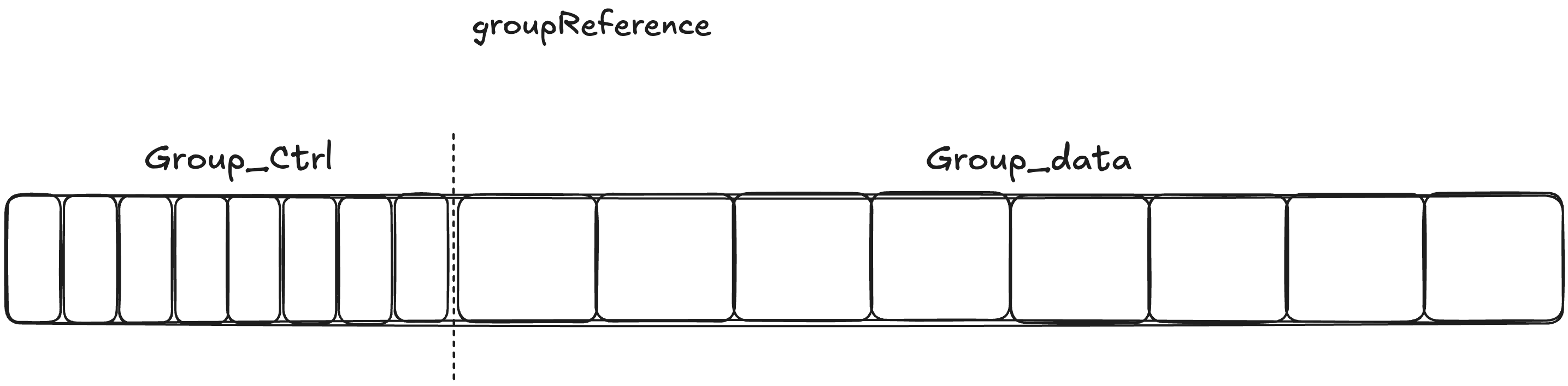

// 多个组
type groupsReference struct {
// 指向一个 group 数组的起始地址
data unsafe.Pointer // data *[length]typ.Group
// lengthMask = length(group的数量) - 1
// 要求 length 一定是 2 的幂,可以用 lengthMask 位运算快速取模
// 在计算某个 key 应该落到那个 group 的时候
// 利用 h1 & lengthMask 代替 h1 % length,加速操作
lengthMask uint64
}
// 单个组 —— group
type groupReference struct {
// data points to the group, which is described by typ.Group and has
// layout:
//
// type group struct {
// ctrls ctrlGroup
// slots [abi.MapGroupSlots]slot
// }
//
// type slot struct {
// key typ.Key
// elem typ.Elem
// }
data unsafe.Pointer // data *typ.Group
}
在 groupReference 的注释中可以看出,单个组内的内存分布情况。这两个结构体都是有一个指针指向一块连续的内存空间,其中,groupReference 指向一个组,而 groupsReference 指向一个 [length]groupReference。
lengthMask:lengthMask = groupLength - 1。当我们求一个 key 落到哪个 group 的时候,是用 h1 % groupLength 以获取的,而这个取模操作实际上可以用位运算来代替。即 h1 % groupLength = h1 & (groupLength - 1) ,而位运算是比除法快的。
3.1.2 Table
Table 是对 groupsReference 的上层封装,因为 groupsReference 实际上只负责存储数据,少了很多关键字段,而 Table 是对 groupsReference 的进一步封装,一个 Table 底层对应一个 groupReference,对应多个组,所以我们在理解 Table 的时候,把一个 Table 理解为一个 SwissTable 即可。
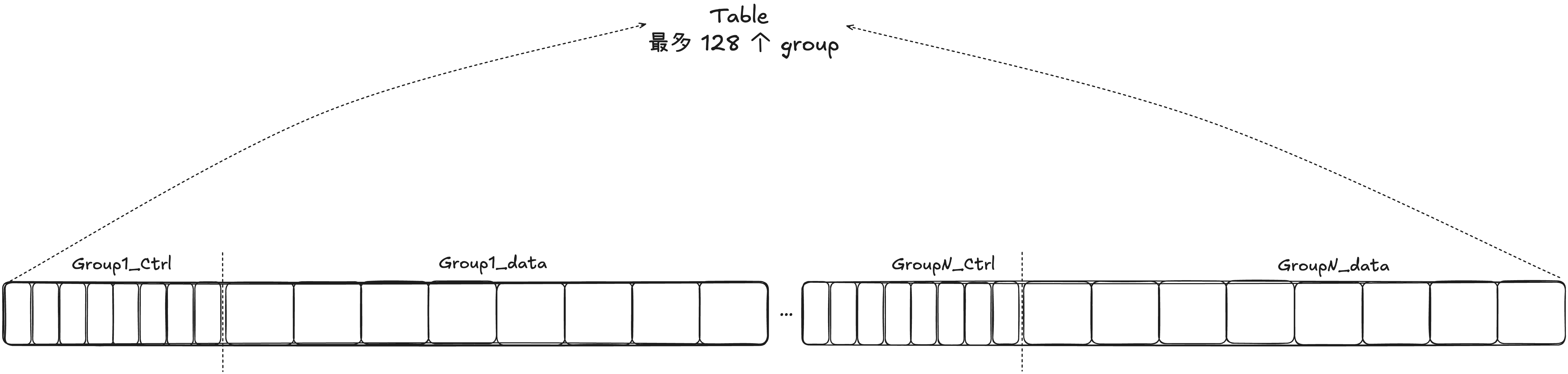 一个 Table 中最多能有 1024 个 Slot,转为 Group 即一个 Table 中最多 128 个 Group(一个 Group 中固定 8 个 Slot)。
一个 Table 中最多能有 1024 个 Slot,转为 Group 即一个 Table 中最多 128 个 Group(一个 Group 中固定 8 个 Slot)。
type table struct {
// 表中元素的个数
used uint16
// 表的槽的数量,因为一个表中包含多个 group,
// 所以表的总槽数 = group 数 * 一个 group 中的 slot 数
capacity uint16
// 表在下次触发 rehash 之前还能插入多少数据
// rehash 是指触发扩容或者 rehash
growthLeft uint16
// 这一位实际上是当前 table 使用的目录位深度
// 当我们在扩容 table 分裂的时候,用来定位 table 的位数也在上涨
// 这时 2 ^ (globalDepth - localDepth)
// 用来标识当前 table 被几个页目录共享(详细看后文)
localDepth uint8
// 该 table 在 map 目录中的索引的起始位置(因为一个表可能被多个连续目录项指向)
index int
// 一个 group 数组的引用,真正存储数据的地方
groups groupsReference
}
used:标识当前 table 中有多少 kv 对。 capacity:标识当前 table 中的总槽数(group 数 * 8)。 growthLeft:在下次触发 rehash(扩容) 之前,还能插入多少 kv 对。 localDepth:标识的是该 table 所处的深度。该字段要结合 Map 中的 globalDepth 来理解。看后文中的扩容。 index:因为在 Map 中可能会有多个目录项都指向同一个 table,所以 index 记录 Map 的表目录中,第一个所处的索引,例如表目录中,4、5 都指向该 table,那么这个 table 的 index 就是 4。 groups:指向真正存储数据的 group 数组。
3.1.3 Map
Map 结构体,我们每次创建一个 Map 的时候,实际上就是创建了一个 Map 结构体
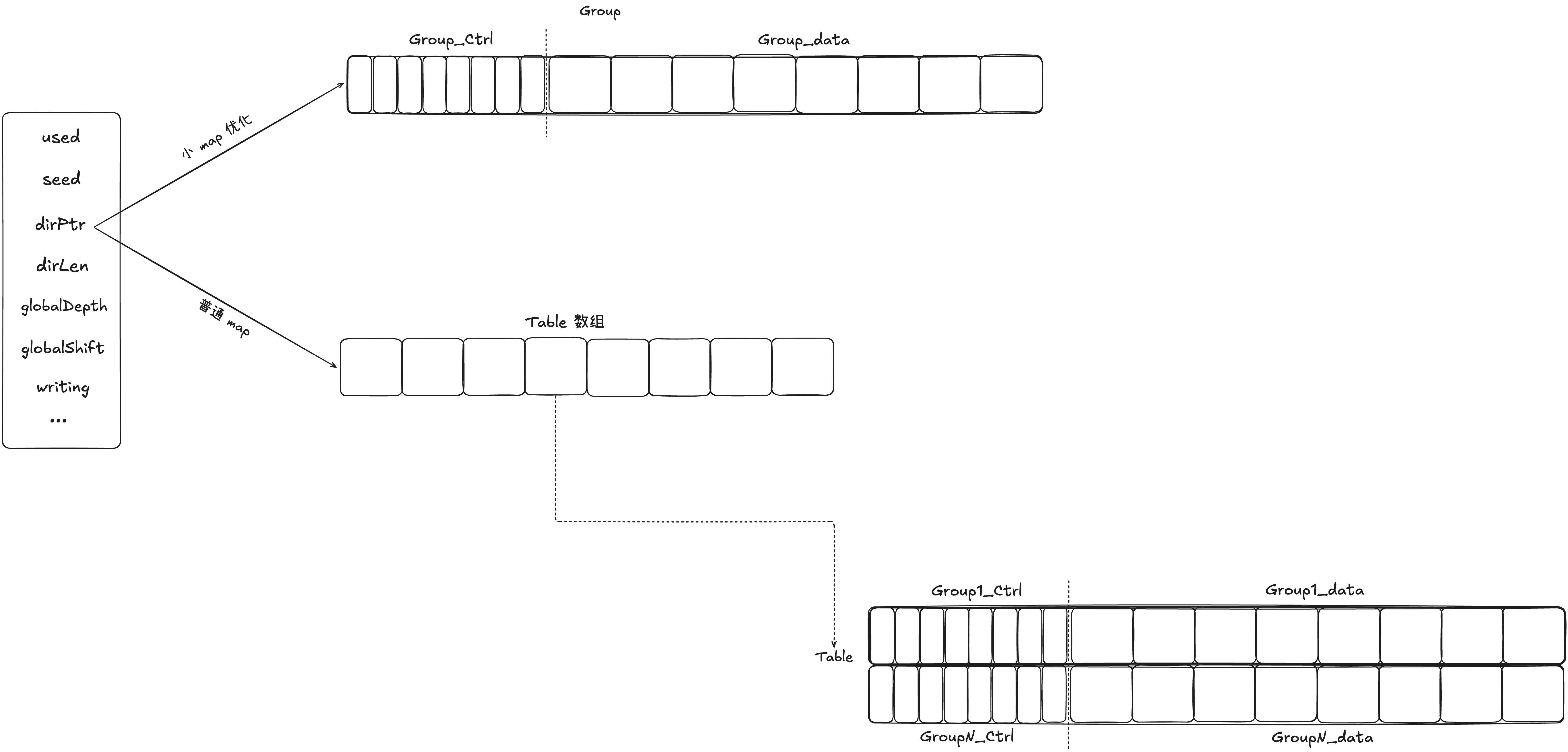
type Map struct {
// map中当前有多少 slot 被占了,数值等于 map 中的 kv 对
used uint64
// 随机 hash 种子
seed uintptr
// 表目录,这个目录指向 map 中所有的 table
// 一个 table 内地址连续,一个 table 内包含多个 group
// 当小表优化的时候,该字段指向一个 group
dirPtr unsafe.Pointer
// 目录长度
dirLen int
// 使用 hash 的多少位来定位 table
globalDepth uint8
// 需要右移多少位来定位 table,这个值在 64 位平台是 64 - globalDepth
globalShift uint8
// 是否有协程在写
writing uint8
// 墓碑位标记(Clear 的时候会用,暂时可以不用看)
tombstonePossible bool
clearSeq uint64
}
used:标记当前 map 中有多少 kv 对,反过来就是有多少 slot 被占用了 seed:随机 hash 种子,创建表的时候会 rand 生成一次,在 map 中 kv 被清空的时候,又会重新生成一次,主要是处于安全性的考量 dirPtr:指向真实存储数据的地方,其指向有两种可能。如果是当前 map 中预估的数据量很小,不超过 8 个 kv,则会创建小 map,也就是直接将 dirPtr 指向一个 Group;如果当前数据量增大了或者一开始创建请求的量就比较大,此时 dirPtr 会指向一个 Table 数组,里面存储一个或多个 Table。 dirLen:table 目录的长度。 globalDepth:全局表的深度,其表示需要 h1 的高多少位来选择 table 数组中的 table。随着 table 数量的增加,需要的位数也会越多。 writing:写标记位,依旧不支持并发安全哦。
3.2 Go SwissTable 实现
下面分别从 Map 的创建、搜索、插入、删除、扩容以及遍历的 Go 的实现逐一展开,并且结合相关源码。
3.2.1 创建
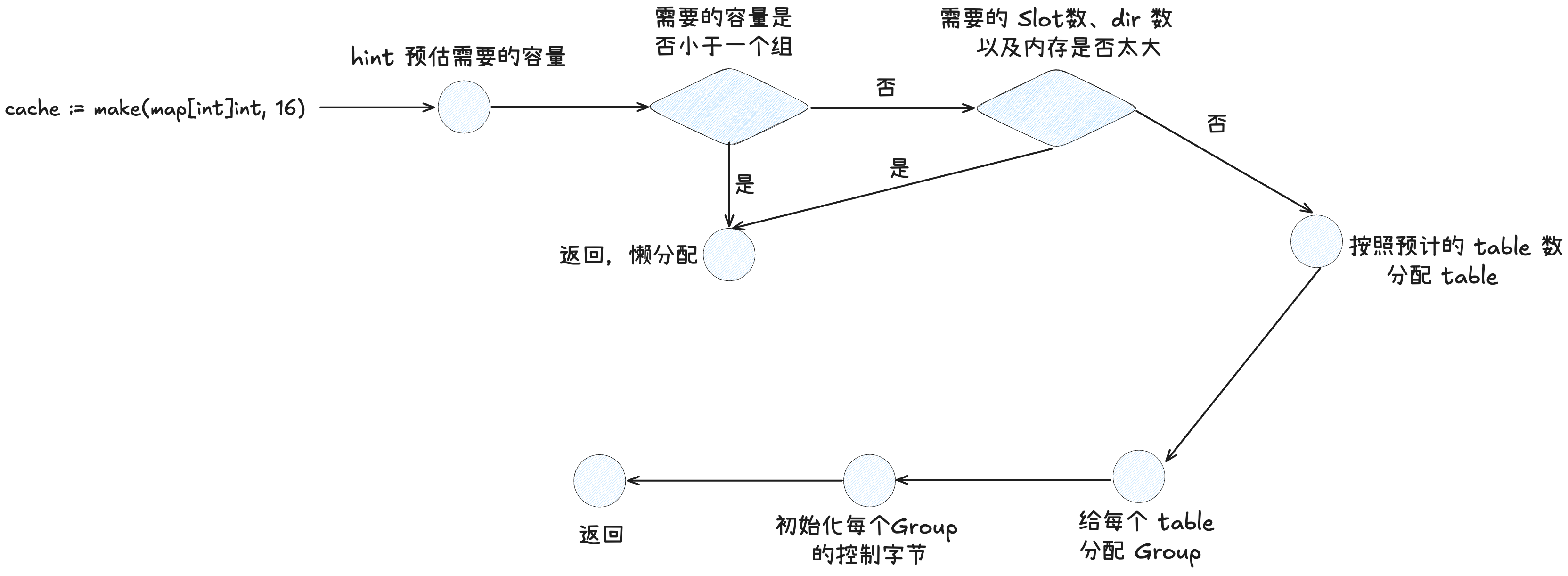
func NewMap(mt *abi.MapType, hint uintptr, m *Map, maxAlloc uintptr) *Map {
// 未指定 map,则创建一个空 Map 对象
if m == nil {
m = new(Map)
}
// 设置随机 Hash 种子
m.seed = uintptr(rand())
// 当预估插入数量小于组内的槽数时,小表优化
if hint <= abi.MapGroupSlots {
// 这里懒分配,插入的时候再进行分配
return m
}
// 计算按装载因子来装载,装满hint个元素需要多少 slot (MapGroupSlots = 8)
// 换言之分配多少 slot 不会超过装载因子
targetCapacity := (hint * abi.MapGroupSlots) / maxAvgGroupLoad
if targetCapacity < hint { // overflow
return m // return an empty map.
}
// maxTableCapcity = 1024 单张表存储的 slot 上限
// 首先把目标槽数按每张表的最大容量来分,计算出需要多少张表
// 然后将表的数量对齐到 2 ^ N,对齐到 2 ^ N有诸多好处,方便位操作
// 而且在扩容的时候也有好处
dirSize := (uint64(targetCapacity) + maxTableCapacity - 1) / maxTableCapacity
dirSize, overflow := alignUpPow2(dirSize)
if overflow || dirSize > uint64(math.MaxUintptr) {
return m // return an empty map.
}
// hint 明显过大,懒分配,返回空 map
groups, overflow := math.MulUintptr(uintptr(dirSize), maxTableCapacity)
if overflow {
return m // return an empty map.
} else {
mem, overflow := math.MulUintptr(groups, mt.GroupSize)
if overflow || mem > maxAlloc {
return m // return an empty map.
}
}
// log2(dirSize) globalDepth 需要几位来定位 Table
m.globalDepth = uint8(sys.TrailingZeros64(dirSize))
// 平台位数 - globalDepth 计算出取 globalDepth 的时候需要右移多少位
m.globalShift = depthToShift(m.globalDepth)
// 给 dir 开辟空间,能走到这里证明不需要小表优化
// 所以 dir 指向的一定是 table
directory := make([]*table, dirSize)
// 按照目录项数,分别分配 table
for i := range directory {
directory[i] = newTable(mt, uint64(targetCapacity)/dirSize, i, m.globalDepth)
}
m.dirPtr = unsafe.Pointer(&directory[0])
m.dirLen = len(directory)
return m
}
(1)如果调用方没有预创建 Map 传入,则创建一个新的 Map,并设置随机 Hash 种子
// 未指定 map,则创建一个空 Map 对象
if m == nil {
m = new(Map)
}
// 设置随机 Hash 种子
m.seed = uintptr(rand())
(2)当预估的容量很小的时候(小 map 模式,也就是预计插入容量小于 8 个 slot),会采用懒分配,等到插入的时候再分配具体的存储区域。
// 当预估插入数量小于组内的槽数时,小表优化
if hint <= abi.MapGroupSlots {
// 这里懒分配,插入的时候再进行分配
return m
}
(3)会按照负载因子计算,分配多少个 slot 不会超过负载因子,因为一组最大只能存 8 个 slot。如果计算完发现 targetCapacity < hint 预估容量,则代表溢出了,暂时不分配存储空间,等插入的时候动态分配。
targetCapacity := (hint * abi.MapGroupSlots) / maxAvgGroupLoad
if targetCapacity < hint { // overflow
return m // return an empty map.
}
(4)因为单个 table 上限是只有 1024 个 slot,128 个 group,所以要根据预估的 slot 数计算需要多少个 table。这里要求 table 的数量一定是 2^N,向 2 对齐有诸多好处。比如说预估需要 3 个 table,则会将 table 数对齐到 4。如果溢出了,则也是采用懒分配。
dirSize := (uint64(targetCapacity) + maxTableCapacity - 1) / maxTableCapacity
dirSize, overflow := alignUpPow2(dirSize)
if overflow || dirSize > uint64(math.MaxUintptr) {
return m // return an empty map.
}
(5)接着是计算有没有能力一次性分配这么多空间,如果没有,则懒分配
groups, overflow := math.MulUintptr(uintptr(dirSize), maxTableCapacity)
if overflow {
return m // return an empty map.
} else {
mem, overflow := math.MulUintptr(groups, mt.GroupSize)
if overflow || mem > maxAlloc {
return m // return an empty map.
}
}
(6)接着就是分配对应的空间,与初始化 Map 中的字段。先初始化全局目录深度字段。接着会给表目录分配空间(代码能执行到这里,一定不是小 map,小 map 会在前面懒分配直接返回)。接着就是给每个表分配内存空间。
// log2(dirSize) globalDepth 需要几位来定位 Table
m.globalDepth = uint8(sys.TrailingZeros64(dirSize))
// 平台位数 - globalDepth 计算出取 globalDepth 的时候需要右移多少位
m.globalShift = depthToShift(m.globalDepth)
// 给 dir 开辟空间,能走到这里证明不需要小表优化
// 所以 dir 指向的一定是 table
directory := make([]*table, dirSize)
// 按照目录项数,分别分配 table
for i := range directory {
directory[i] = newTable(mt, uint64(targetCapacity)/dirSize, i, m.globalDepth)
}
m.dirPtr = unsafe.Pointer(&directory[0])
m.dirLen = len(directory)
return m
下面就是创建单个 table 的逻辑,代码也很简单,主要是做一些校验,然后会调用 reset(),真正给表内分配 groupsReference,也就是真实存储数据的连续内存。这里的代码比较简单,看我的注释即可。
func newTable(typ *abi.MapType, capacity uint64, index int, localDepth uint8) *table {
// 检查单表 solt 数,如果少于单组最小 slot 数,则对齐到单表最小 slot 数
if capacity < abi.MapGroupSlots {
capacity = abi.MapGroupSlots
}
t := &table{
index: index,
localDepth: localDepth,
}
// 检查 slot 数有没有超过单表最大 slot 数
if capacity > maxTableCapacity {
panic("initial table capacity too large")
}
// slot 数对齐到 2 的幂
// 这里对齐后 slot 数一定是 8 的倍数,也就是一定可以分成一定数量的 group
capacity, overflow := alignUpPow2(capacity)
if overflow {
panic("rounded-up capacity overflows uint64")
}
// 真实分配真正的存储部分
// 按照 capacity 计算出组数,接着按照组数分配出一片内存空间作为该 table
// 按照 group 和 map 元数据计算出每组所在的位置,并且将对应组的控制数组置为 empty
t.reset(typ, uint16(capacity))
return t
}
// 为 table 创建真正存储数据的地方,并且初始化每个组的控制字节
func (t *table) reset(typ *abi.MapType, capacity uint16) {
// 按照总 slot 数,计算组数
groupCount := uint64(capacity) / abi.MapGroupSlots
// 分配底层的数组(注意,一个 table 内的组占用的是一块连续的地址)
t.groups = newGroups(typ, groupCount)
t.capacity = capacity
// 计算 rehash 前,还能插入多少元素
t.growthLeft = t.maxGrowthLeft()
// 初始化每个 group 的 控制字节位 empty
for i := uint64(0); i <= t.groups.lengthMask; i++ {
g := t.groups.group(typ, i)
g.ctrls().setEmpty()
}
}
// 按照组数分配一片内存用来存储每个组
func newGroups(typ *abi.MapType, length uint64) groupsReference {
return groupsReference{
data: newarray(typ.Group, int(length)),
lengthMask: length - 1,
}
}
3.2.2 搜索
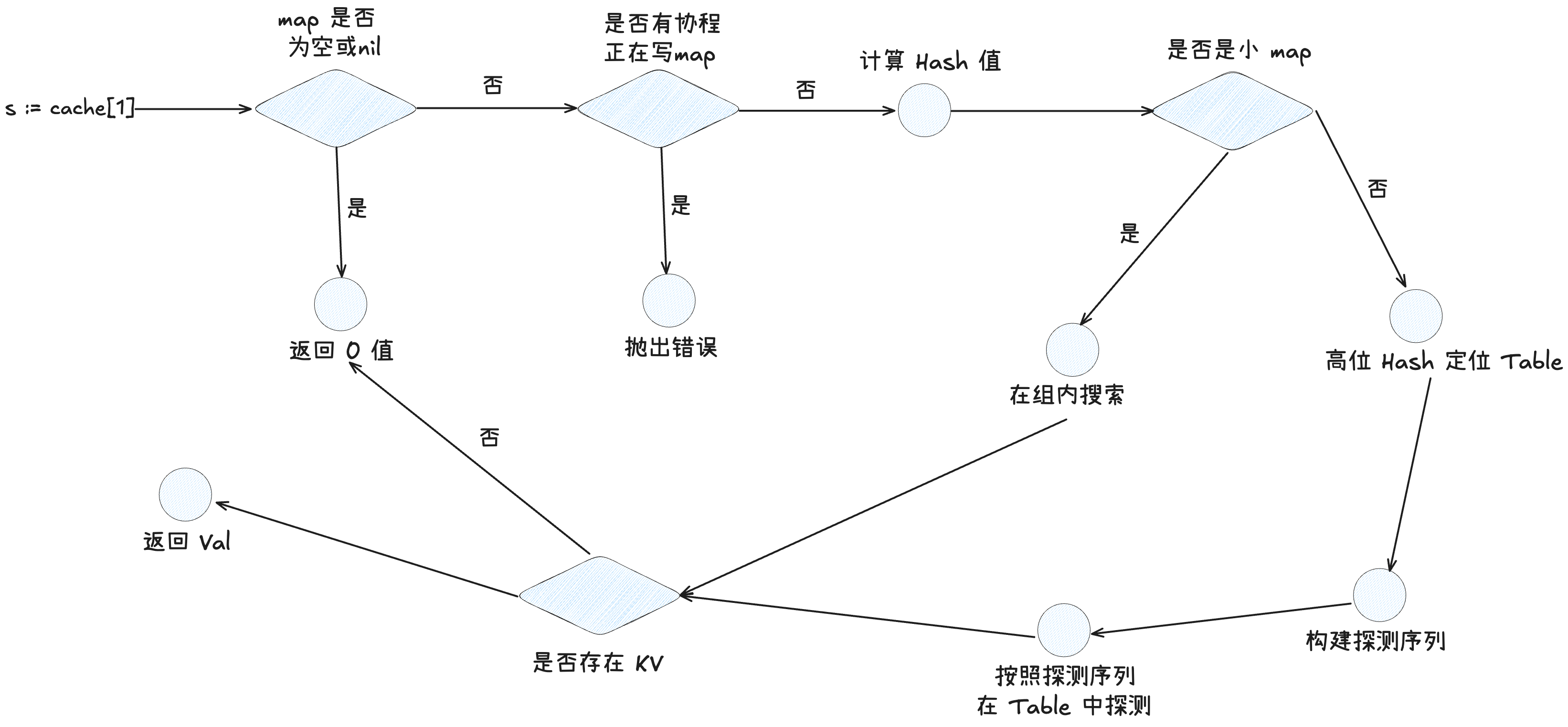 通过指定 Key 获取 map 中元素的依旧对应两个方法,分别是
通过指定 Key 获取 map 中元素的依旧对应两个方法,分别是 runtime_mapaccess1() 和 runtime_mapaccess2() 这里围绕 1 展开,关注具体的搜索细节。
func runtime_mapaccess1(typ *abi.MapType, m *Map, key unsafe.Pointer) unsafe.Pointer {
// 竞态检测或内存检测
// ...
// 如果 m 是 nil 或者空,直接返回零值
if m == nil || m.Used() == 0 {
if err := mapKeyError(typ, key); err != nil {
panic(err) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// 并发读写报错
if m.writing != 0 {
fatal("concurrent map read and map write")
}
// 根据 key 计算出 hash 值
hash := typ.Hasher(key, m.seed)
// 如果 dirlen <= 0 的时候是小 map
if m.dirLen <= 0 {
// 走小 map 的查询流程
_, elem, ok := m.getWithKeySmall(typ, hash, key)
if !ok {
// 小 map 中查询没有,则直接返回零值
return unsafe.Pointer(&zeroVal[0])
}
return elem
}
// Select table.
// 根据 hash 值定位 table_idx,这里实际上就是用 hash 的高位去判断属于哪个 table
idx := m.directoryIndex(hash)
// 获取到具体的 table (table 包含了多个 group)
t := m.directoryAt(idx)
// Probe table.
// 按照 h1 & lengthmask,获取一个探测序列
// 也就是说一样的 key,探测序列一定一样,从同一个起始点出发
seq := makeProbeSeq(h1(hash), t.groups.lengthMask)
// hash 值的低 7 位
h2Hash := h2(hash)
for ; ; seq = seq.next() {
// 根据探测序列获取到具体的组
g := t.groups.group(typ, seq.offset)
// 返回该组中和该 h2 匹配的 slot
match := g.ctrls().matchH2(h2Hash)
// match != 0 ==> match 中只要有一位是 1 ==> 这组中至少有一个 key 匹配上了
for match != 0 {
i := match.first()
// 对比
slotKey := g.key(typ, i)
slotKeyOrig := slotKey
if typ.IndirectKey() {
slotKey = *((*unsafe.Pointer)(slotKey))
}
if typ.Key.Equal(key, slotKey) {
slotElem := unsafe.Pointer(uintptr(slotKeyOrig) + typ.ElemOff)
if typ.IndirectElem() {
slotElem = *((*unsafe.Pointer)(slotElem))
}
return slotElem
}
// 移除匹配到的槽,循环继续查找
match = match.removeFirst()
}
// 到这里有两种可能:
// 1. 组内匹配完毕,发现没有匹配的 KV
// 2. match = 0,即这一组内没有 K 与目标 Key 匹配
// 检测该组有没有 empty 槽
match = g.ctrls().matchEmpty()
// 如果有 empty 槽,则直接返回对应类型的 0 值
if match != 0 {
// Finding an empty slot means we've reached the end of
// the probe sequence.
return unsafe.Pointer(&zeroVal[0])
}
// seq.next() 中只有取模,没有边界 check
// 负载因子的存在保证了 table 一定有空 slot
// 所以只有两种可能性,一种是存在 key 并且找到
// 另外一种是 key 不存在,找到了空槽,结束查找
}
}
(1)如果 map 为空或者为 nil,则直接返回对应 val 类型的零值。
if m == nil || m.Used() == 0 {
if err := mapKeyError(typ, key); err != nil {
panic(err) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
(2)查看是否有协程正在并发写入 map,如果有则直接 fatel,否则计算出查询 key 的 hash 值
// 并发读写报错
if m.writing != 0 {
fatal("concurrent map read and map write")
}
hash := typ.Hasher(key, m.seed)
(3)查看是否是小 map,如果是小 map,则走小 map 的查询逻辑(因为如果是小 map,则 Map 中的 dirPtr 字段直接指向的是一个 group,而不是 table 数组)
// 如果 dirlen <= 0 的时候是小 map
if m.dirLen <= 0 {
// 走小 map 的查询流程
_, elem, ok := m.getWithKeySmall(typ, hash, key)
if !ok {
// 小 map 中查询没有,则直接返回零值
return unsafe.Pointer(&zeroVal[0])
}
return elem
}
(4)通过 hash 值的高几位去定位该 k 所处的 Table,具体取高多少位随着 map 扩容会动态改变,主要参考 globalShift 和 globalDepth 字段。定位到具体的 Table 后,会根据 Key 的 h1 定位 table 中所处的 group,进而生成一个探测序列。(探测序列就是指从那个 group 开始搜索,因为线性探测法会导致 kv 落在其他 group 的 slot 中。同一个 key 的探测序列是一致的)
func (m *Map) directoryIndex(hash uintptr) uintptr {
if m.dirLen == 1 {
return 0
}
// (m.globalShift & 63) 计算定位 table 需要右移的位数
// hash 右移 x 位,进而定位到具体的 table
return hash >> (m.globalShift & 63)
}
// 根据 hash 值定位 table_idx,这里实际上就是用 hash 的高位去判断属于哪个 table
idx := m.directoryIndex(hash)
// 获取到具体的 table (table 包含了多个 group)
t := m.directoryAt(idx)
// Probe table.
// 按照 h1 & lengthmask,获取一个探测序列
// 也就是说一样的 key,探测序列一定一样,从同一个起始点出发
seq := makeProbeSeq(h1(hash), t.groups.lengthMask)
// hash 值的低 7 位
h2Hash := h2(hash)
(5)按照探测序列一个一个组的探测,组内的探测流程可以见下一小节中的小 map 探测。当一个组匹配完,如果没有找到目标 k,则会探测下一个组,直到探测到空的 Slot 或者目标 key。这里实际上是有两个我们要知道的前提:
- 因为有负载系数的存在,所以 table 一定不会存满,也就是说 table 中一定有状态为 empty 的 Slot。
- 如果当前组内有一个 empty 的 slot,那么目标 key 要么存在于当前组,要么不存在,不可能存在于要探测的下一个组。(因为在删除元素的时候,会将位置置为 deleted 而不是 empty)
基于上面两个大的前提,代码也就很明了了,会在判断完当前探测的组内是否有 key 后,如果没有,则会进一步判断当前组内是否有 empty 槽,如果有,则会停止探测下一个组。
for ; ; seq = seq.next() {
// 根据探测序列获取到具体的组
g := t.groups.group(typ, seq.offset)
// 返回该组中和该 h2 匹配的 slot
match := g.ctrls().matchH2(h2Hash)
for match != 0 {
i := match.first()
// 对比
slotKey := g.key(typ, i)
slotKeyOrig := slotKey
if typ.IndirectKey() {
slotKey = *((*unsafe.Pointer)(slotKey))
}
if typ.Key.Equal(key, slotKey) {
slotElem := unsafe.Pointer(uintptr(slotKeyOrig) + typ.ElemOff)
if typ.IndirectElem() {
slotElem = *((*unsafe.Pointer)(slotElem))
}
return slotElem
}
// 移除匹配到的槽,循环继续查找
match = match.removeFirst()
}
match = g.ctrls().matchEmpty()
if match != 0 {
return unsafe.Pointer(&zeroVal[0])
}
}
小 map 搜索流程(单个组的搜索流程)
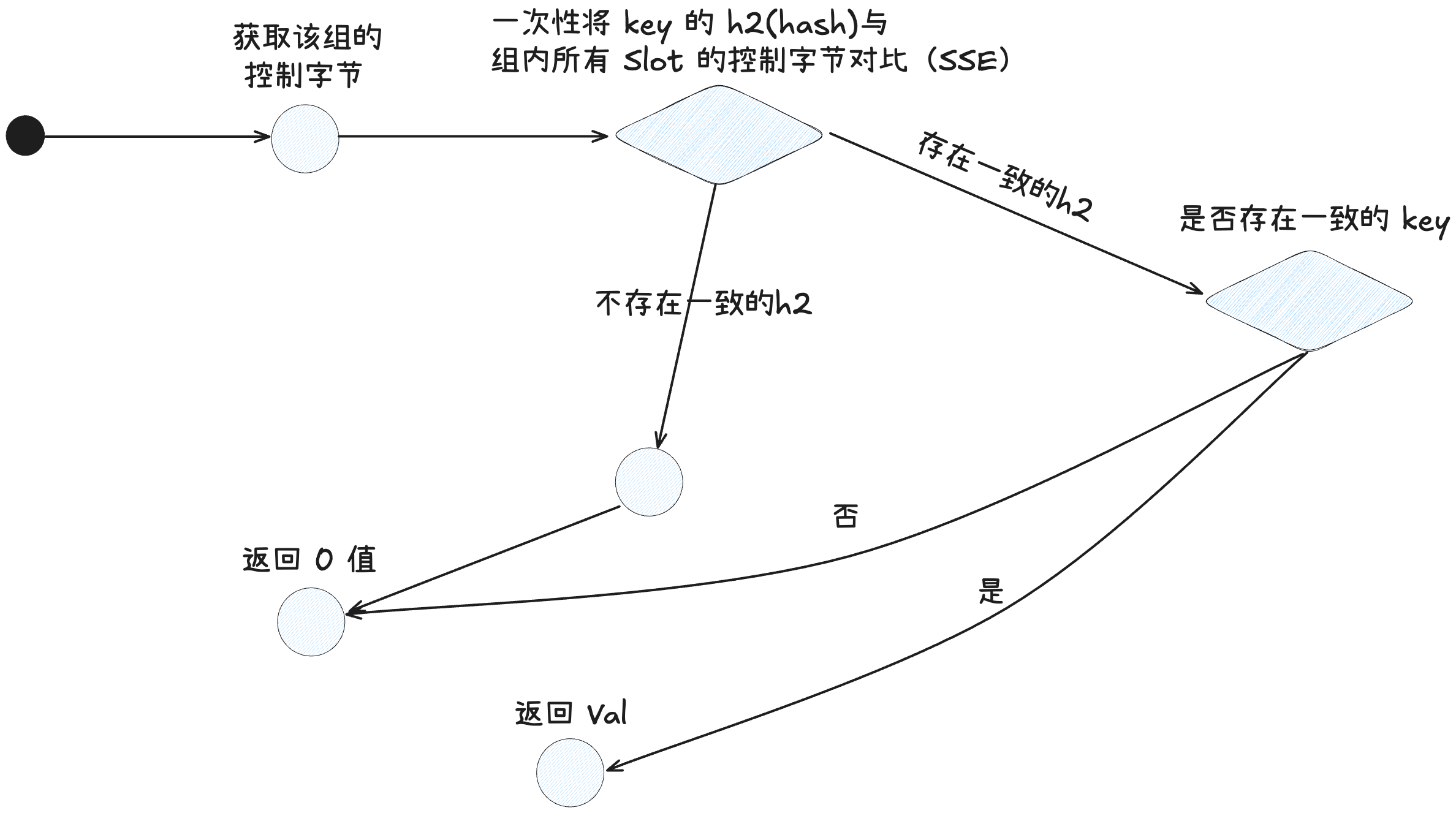
func (m *Map) getWithKeySmall(typ *abi.MapType, hash uintptr, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer, bool) {
// 当小 map 的时候,dir 指针指向的不是 table 数组,而是一个单个的 group
// 所以这里能直接获取到这个 group
g := groupReference{
data: m.dirPtr,
}
// h2(hash) 获取低 7 位
// 这里得到一个 64 位bitset,其中每个字节的最高位如果为 1 代表该字节对应的 slot 匹配成功
match := g.ctrls().matchH2(h2(hash))
for match != 0 {
// 获取第一个匹配到的槽的 idx
i := match.first()
// 根据索引 取到 key
slotKey := g.key(typ, i)
if typ.IndirectKey() {
slotKey = *((*unsafe.Pointer)(slotKey))
}
// 判断 key 是否相等
if typ.Key.Equal(key, slotKey) {
slotElem := g.elem(typ, i)
if typ.IndirectElem() {
slotElem = *((*unsafe.Pointer)(slotElem))
}
// 相等直接返回
return slotKey, slotElem, true
}
// 将右边第一个 1 置为 0,往左寻找下一个 1(匹配到的槽)
match = match.removeFirst()
}
// No match here means key is not in the map.
// (A single group means no need to probe or check for empty).
// 在 map 中没有找到该 key,直接返回
return nil, nil, false
}
(1)直接获取到 group 数组
g := groupReference{
data: m.dirPtr,
}
(2)接着,通过 matchH2 方法,并行的比较 H2 与 group 中的 8 个slot,然后返回一个 8 字节的 bitset,如果某一个字节是 1,则代表这一字节对应的 slot 与该 key 可能一致,需要进一步比对 key。
match := g.ctrls().matchH2(h2(hash))
const bitsetLSB = 0x0101010101010101 // 每字节最低位 = 1
const bitsetMSB = 0x8080808080808080 // 每字节最高位 = 1
// 返回 H2 匹配到的 slot
func (g ctrlGroup) matchH2(h uintptr) bitset {
return ctrlGroupMatchH2(g, h)
}
// 位运算找到 h2 值匹配的槽
func ctrlGroupMatchH2(g ctrlGroup, h uintptr) bitset {
// bitsetLSB = 0x0101010101010101
// (bitsetLSB * uint64(h)) ==> 乘法广播
// 假设 h2 是 0x42 * bitsetLSB ==> 0x4242424242424242
// 为了和八个槽并行比对,所以这里要把 h 广播到 64 位
// 接着和 g 的 8 个 ctrl 位异或,这里要注意 g 的高位为 0 的时候,才表示这个槽内有数据
// 而 h2 是低 7 位,最高位也是 0,即当 g 与 h 完全匹配的时候,高位异或应该也是 0
// 也就是说,如果某个 ctrl 匹配到了,这个位置 8 个 bit 应该全为 0
// 也就是说,这里的 v 中,如果全为 0 的字节对应的槽,即为匹配上的槽
v := uint64(g) ^ (bitsetLSB * uint64(h))
// bitsetMSB = 0x8080808080808080
// 这一步是检测零字节,返回一个 bitset
// 这个 bitset 的每个字节的最高位如果是 1,则代表匹配
// 比如说 10000000 ==> 则这这一字节对应的 slot 匹配成功
return bitset(((v - bitsetLSB) &^ v) & bitsetMSB)
}
(3)同普通 map 的组内校验。
for match != 0 {
// 获取第一个匹配到的槽的 idx
i := match.first()
// 根据索引 取到 key
slotKey := g.key(typ, i)
if typ.IndirectKey() {
slotKey = *((*unsafe.Pointer)(slotKey))
}
// 判断 key 是否相等
if typ.Key.Equal(key, slotKey) {
slotElem := g.elem(typ, i)
if typ.IndirectElem() {
slotElem = *((*unsafe.Pointer)(slotElem))
}
// 相等直接返回
return slotKey, slotElem, true
}
// 将右边第一个 1 置为 0,往左寻找下一个 1(匹配到的槽)
match = match.removeFirst()
}
(4)没找到则 `return nil, nil, false
3.2.3 插入
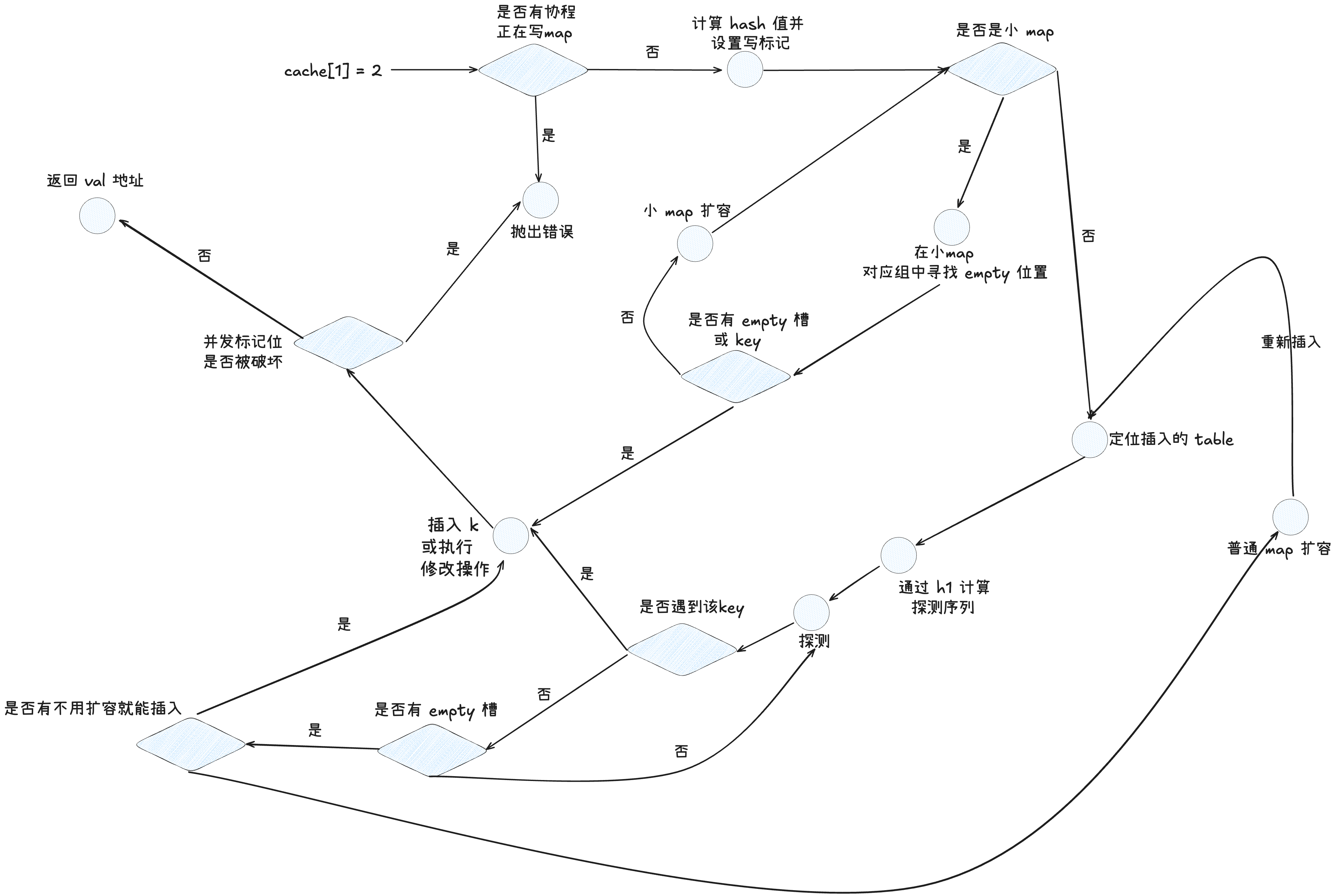 插入指定的 kv 对,如果 kv 对存在,则修改 k 对应的 v 值。
插入指定的 kv 对,如果 kv 对存在,则修改 k 对应的 v 值。
//go:linkname runtime_mapassign runtime.mapassign
// 插入值,这里依旧是找到插入的位置后,返回对应的地址,由上层调用方插入
func runtime_mapassign(typ *abi.MapType, m *Map, key unsafe.Pointer) unsafe.Pointer {
// 工具配置...
// ...
if m.writing != 0 {
fatal("concurrent map writes")
}
// 求出 key 的 hash 值
hash := typ.Hasher(key, m.seed)
// 设置写 flag
m.writing ^= 1
// 如果 dirPtre = nil,代表是小map,小表优化懒加载
if m.dirPtr == nil {
// 创建小表并且初始化
m.growToSmall(typ)
}
// dirlen == 0 代表是小表
if m.dirLen == 0 {
if m.used < abi.MapGroupSlots {
// 组内还有空余 slot
elem := m.putSlotSmall(typ, hash, key)
if m.writing == 0 {
fatal("concurrent map writes")
}
// 恢复写 flag
m.writing ^= 1
return elem
}
// 没有找到空位,则从小 map (group)扩容成 table,后往下执行 table 的插入流程
m.growToTable(typ)
}
// 找到第一个可以插入的位置
var slotElem unsafe.Pointer
outer:
for {
// Select table.
// 根据 hash 定位到 table
idx := m.directoryIndex(hash)
t := m.directoryAt(idx)
// 创建探测序列
seq := makeProbeSeq(h1(hash), t.groups.lengthMask)
// 第一个有删除状态的 group 和对应的 slot,可以用这个 slot 插入新的元素
var firstDeletedGroup groupReference
var firstDeletedSlot uintptr
h2Hash := h2(hash)
// 按照探测序列探测
for ; ; seq = seq.next() {
g := t.groups.group(typ, seq.offset)
// 找到 group 内 hash 一致的 slot
match := g.ctrls().matchH2(h2Hash)
// Look for an existing slot containing this key.
// 遍历 bitset,看是否存在一样的 key
for match != 0 {
i := match.first()
slotKey := g.key(typ, i)
slotKeyOrig := slotKey
if typ.IndirectKey() {
slotKey = *((*unsafe.Pointer)(slotKey))
}
if typ.Key.Equal(key, slotKey) {
// 匹配成功,更新 key
if typ.NeedKeyUpdate() {
typedmemmove(typ.Key, slotKey, key)
}
slotElem = unsafe.Pointer(uintptr(slotKeyOrig) + typ.ElemOff)
if typ.IndirectElem() {
slotElem = *((*unsafe.Pointer)(slotElem))
}
t.checkInvariants(typ, m)
// 退出
break outer
}
// 找下一个 group
match = match.removeFirst()
}
// 代码走到这里代表没有 table 中没有一致的 key,但是此时探测序列可能还没有结束
// 获取 group 中的 empty slot
match = g.ctrls().matchEmpty()
// 注意这里是 if match 不是 for match
if match != 0 {
// 找到空槽意味着到达了探测序列的终点
var i uintptr
// 如果之前有墓碑位,则使用墓碑位插入
if firstDeletedGroup.data != nil {
g = firstDeletedGroup
i = firstDeletedSlot
// 等于暂时将墓碑位所占据的位置释放
// 逻辑上就是 table 多了一个能插入的位置
t.growthLeft++
} else {
// Otherwise, use the empty slot.
// 如果没有墓碑槽,这里直接用空槽
i = match.first()
}
// If there is room left to grow, just insert the new entry.
// 如果在 rehash 之前还能插入,则直接插入
if t.growthLeft > 0 {
slotKey := g.key(typ, i)
slotKeyOrig := slotKey
if typ.IndirectKey() {
kmem := newobject(typ.Key)
*(*unsafe.Pointer)(slotKey) = kmem
slotKey = kmem
}
typedmemmove(typ.Key, slotKey, key)
slotElem = unsafe.Pointer(uintptr(slotKeyOrig) + typ.ElemOff)
if typ.IndirectElem() {
emem := newobject(typ.Elem)
*(*unsafe.Pointer)(slotElem) = emem
slotElem = emem
}
// 设置 slot 对应的控制字节,可插入位置 --
g.ctrls().set(i, ctrl(h2Hash))
t.growthLeft--
t.used++
m.used++
// 退出
t.checkInvariants(typ, m)
break outer
}
// 走到这里代表此时虽然表内有空槽
// 但是整个表已经达到负载边界,需要扩容 rehash
t.rehash(typ, m)
// 因为 rehash 了,所以直接重新走一遍插入流程
continue outer
}
// 这里尝试找有没有墓碑(delete 槽)
// 如果找到,则将 delete 槽赋值给变量,后面会将元素插入该位置
if firstDeletedGroup.data == nil {
// Since we already checked for empty slots
// above, matches here must be deleted slots.
match = g.ctrls().matchEmptyOrDeleted()
if match != 0 {
firstDeletedGroup = g
firstDeletedSlot = match.first()
}
}
}
}
// 检查写状态有没有被破坏
if m.writing == 0 {
fatal("concurrent map writes")
}
m.writing ^= 1
// 返回插入位置
return slotElem
}
(1)检测是否有其他协程在并发写 map,如果没有则计算出 key 的 hash 值,并且设置写标记,否则,抛出错误。
if m.writing != 0 {
fatal("concurrent map writes")
}
// 求出 key 的 hash 值
hash := typ.Hasher(key, m.seed)
// 设置写 flag
m.writing ^= 1
(2) 如果是小 map 的话,在创建的时候会采用懒加载的方式分配空间,所以在这里插入元素的时候,需要分配对应的空间。在 growToSmall 中,将开辟一个单位大小的 group 给 Map,Map 的表目录指针也会指向这组。
func (m *Map) growToSmall(typ *abi.MapType) {
// 创建一个新的 group,长度为 1
grp := newGroups(typ, 1)
m.dirPtr = grp.data
g := groupReference{
data: m.dirPtr,
}
// 组内控制置空
g.ctrls().setEmpty()
}
if m.dirPtr == nil {
// 创建小表并且初始化
m.growToSmall(typ)
}
(3)如果 dirlen <= 0,代表此时是小 map,则进入小 map 的插入流程。首先会 check 这个组内是否有空的槽,如果有,则会调用 putSoltSmall() 插入。
在 putSoltSmall() 中
- 首先会先通过hash 值的 h2,在组内找到所有 h2 一致的 slot,与前面的查找过程一致。如果找到了,则会直接进行赋值,然后返回。如果没找到,则会进入插入流程。
- 插入流程中,首先会检查是否有空余的位置,通过
matchEmptyOrDeleted()方法,类似匹配 h2 一样,生成一个 bitset,如果此时发现没有空槽,则会直接报错,因为在进入putSoltSmall()之前检查是有空 Slot 的,现在没有代表发生了并发写入操作。 - 找到第一个空槽后,会将 Key 插入,然后预插入 Val,然后将对应的控制字节改为 key 的 h2 值 + 高位 0,代表 Full 状态,最后将 used 数值 + 1,返回 val 的地址,由上层写入。
(注意,这里在小 map 中,检查空余元素用的是
matchEmptyOrDeleted()方法,也就是不分 deleted 状态和 empty 状态,这是为什么?因为在一个组内,是不是遇到 empty 就搜索早停的,搜索早停是指在当前组内发现了 empty slot,则可以停止搜索下一组)
如果成功在小 map 中插入了,则会检查是否有并发写冲突,如果有,则报错,如果没有则修改写标记位,并且返回 val 的地址。而如果没有成功插入,也就是小 map 中没有空槽,则会调用growToTable()将 group 升级为 table,真正的进化成 SwissTable,接着往下走普通 map 的插入流程。这里的内容暂时不展开,具体见扩容流程(第 5 小节)。
if m.dirLen == 0 {
if m.used < abi.MapGroupSlots {
// 组内还有空余 slot
elem := m.putSlotSmall(typ, hash, key)
if m.writing == 0 {
fatal("concurrent map writes")
}
// 恢复写 flag
m.writing ^= 1
return elem
}
// 没有找到空位,则从小 map (group)扩容成 table,后往下执行 table 的插入流程
m.growToTable(typ)
}
func (m *Map) putSlotSmall(typ *abi.MapType, hash uintptr, key unsafe.Pointer) unsafe.Pointer {
// 直接获取组的数组
g := groupReference{
data: m.dirPtr,
}
// 返回匹配到的 bitset
match := g.ctrls().matchH2(h2(hash))
for match != 0 {
i := match.first()
slotKey := g.key(typ, i)
if typ.IndirectKey() {
slotKey = *((*unsafe.Pointer)(slotKey))
}
// 如果是同一个 key
if typ.Key.Equal(key, slotKey) {
if typ.NeedKeyUpdate() {
typedmemmove(typ.Key, slotKey, key)
}
slotElem := g.elem(typ, i)
if typ.IndirectElem() {
slotElem = *((*unsafe.Pointer)(slotElem))
}
// val 的地址
return slotElem
}
// 当前槽没有匹配成功,往下找下一个可能会匹配成功的槽
match = match.removeFirst()
}
// 代码走到这里代表 map 中不存在这个 key
// 同理,找到 group 内状态为空的槽,小 map 内没有删除这个状态
match = g.ctrls().matchEmptyOrDeleted()
if match == 0 {
// 如果小 map 内不存在空槽,则出错,因为在进入这个函数之前校验过是有空槽的
// 发生这种情况可能是并发写了
fatal("small map with no empty slot (concurrent map writes?)")
return nil
}
// 定位到第一个匹配到的空槽
i := match.first()
// 获取 key 和 v 的地址
slotKey := g.key(typ, i)
if typ.IndirectKey() {
kmem := newobject(typ.Key)
*(*unsafe.Pointer)(slotKey) = kmem
slotKey = kmem
}
// 写入 key
typedmemmove(typ.Key, slotKey, key)
slotElem := g.elem(typ, i)
if typ.IndirectElem() {
emem := newobject(typ.Elem)
*(*unsafe.Pointer)(slotElem) = emem
slotElem = emem
}
// 设置槽对应的控制位为 h2
g.ctrls().set(i, ctrl(h2(hash)))
// kv 数量 + 1
m.used++
// 返回 val 的写入地址,上层写入
return slotElem
}
(4)此时进入大表的插入流程,首先是依据 hash 值的高几位来定要插入的 table,接着会根据 h1 和 group 数创建一个探测序列,指定接下来的探测顺序。
idx := m.directoryIndex(hash)
t := m.directoryAt(idx)
// 创建探测序列
seq := makeProbeSeq(h1(hash), t.groups.lengthMask)
(5)接着按照探测序列逐个 group 进行探测,首先这里会先按照探测序列定位的组,在组内找,是否有一样的 key,如果有,则改为更新操作,并退出探测。否则,往下执行逻辑。
for ; ; seq = seq.next() {
g := t.groups.group(typ, seq.offset)
// 找到 group 内 hash 一致的 slot
match := g.ctrls().matchH2(h2Hash)
// 遍历 bitset,看是否存在一样的 key
for match != 0 {
i := match.first()
slotKey := g.key(typ, i)
slotKeyOrig := slotKey
if typ.IndirectKey() {
slotKey = *((*unsafe.Pointer)(slotKey))
}
if typ.Key.Equal(key, slotKey) {
// 匹配成功,更新 key
if typ.NeedKeyUpdate() {
typedmemmove(typ.Key, slotKey, key)
}
slotElem = unsafe.Pointer(uintptr(slotKeyOrig) + typ.ElemOff)
if typ.IndirectElem() {
slotElem = *((*unsafe.Pointer)(slotElem))
}
t.checkInvariants(typ, m)
// 退出
break outer
}
// 找下一个 group
match = match.removeFirst()
}
// ...
(6)如果在组内,没有找到一样的 key,并不是按照探测序列查找下一个组,而是会检查这组内是否有空的槽,如果这组内有空的槽,则不需要往下进一步查找下一个组了(因为插入不变式,首先插入同一个 Key 一定是走相同的探测序列,而插入是遇到 empty 就会插入,所以后续的组内不可能有这个 key)。
// ...
match = g.ctrls().matchEmpty()
// 注意这里是 if match 不是 for match
if match != 0 {
// 找到空槽意味着到达了探测序列的终点
var i uintptr
// 如果之前有墓碑位,则使用墓碑位插入
if firstDeletedGroup.data != nil {
g = firstDeletedGroup
i = firstDeletedSlot
// 等于暂时将墓碑位所占据的位置释放,
// 逻辑上就是 table 多了一个能插入的位置
t.growthLeft++ // will be decremented below to become a no-op.
} else {
// Otherwise, use the empty slot.
// 如果没有墓碑槽,这里直接用空槽
i = match.first()
}
此时,如果查到该组内有 empty 槽,则会检查在之前探测的组内有没有遇到 deleted 槽(墓碑位),如果有,则会尝试将数据插在 deleted 槽中,复用槽。否则,则会尝试插入到 empty 槽(注意是尝试)。插入之前会校验当前组内的要不要超负载,如果超过负载,会执行 table 扩容,然后扩容后,再重新探测插入(扩容的逻辑在第 5 小节)。
// ...
// 没超过负载,代表还有插入空间
// (growthLeft 是指在 rehash 之前还能插入多少 kv 对)
if t.growthLeft > 0 {
slotKey := g.key(typ, i)
slotKeyOrig := slotKey
if typ.IndirectKey() {
kmem := newobject(typ.Key)
*(*unsafe.Pointer)(slotKey) = kmem
slotKey = kmem
}
typedmemmove(typ.Key, slotKey, key)
slotElem = unsafe.Pointer(uintptr(slotKeyOrig) + typ.ElemOff)
if typ.IndirectElem() {
emem := newobject(typ.Elem)
*(*unsafe.Pointer)(slotElem) = emem
slotElem = emem
}
// 设置 slot 对应的控制字节,可插入位置 --
g.ctrls().set(i, ctrl(h2Hash))
// 空位 --
t.growthLeft--
// 使用位 ++
t.used++
m.used++
// 退出
t.checkInvariants(typ, m)
break outer
}
// 如果超负载了,则执行扩容
t.rehash(typ, m)
// 因为 rehash 了,所以直接重新走一遍插入流程
continue outer
}
假设如果在当前组内没有找到 empty 槽,那代表可以继续往下一组探测了,探测之前会看看之前有没有记录到的墓碑位,如果有就不用再检查当前组内有没有墓碑了,如果没记录过,还要检查一下当前组内有没有墓碑位,主要是为了复用 deleted 槽。
// 这里尝试找有没有墓碑(delete 槽)
// 如果找到,则将 delete 槽赋值给变量,后面会将元素插入该位置
if firstDeletedGroup.data == nil {
// Since we already checked for empty slots
// above, matches here must be deleted slots.
match = g.ctrls().matchEmptyOrDeleted()
if match != 0 {
firstDeletedGroup = g
firstDeletedSlot = match.first()
}
}
(7) 插入完成后,校验写标记有没有被破坏,如果有,则抛出错误,如果没有,则重置写标记位,并且返回 val 的地址,由上层插入。
// 检查写状态有没有被破坏
if m.writing == 0 {
fatal("concurrent map writes")
}
m.writing ^= 1
// 返回插入位置
return slotElem
3.2.4 删除
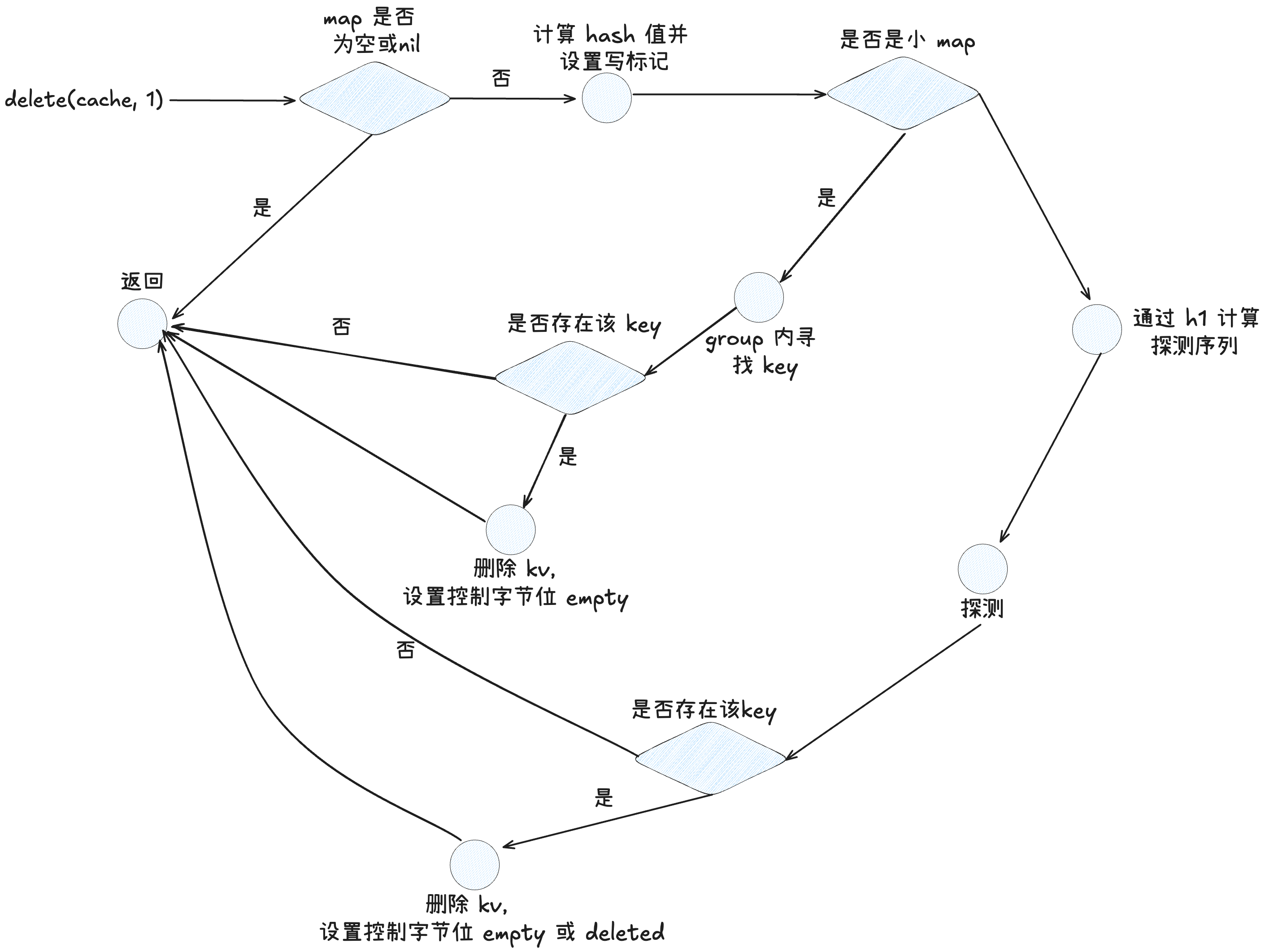
删除操作相对来说简单很多,因为 map 只会扩容,不会缩容,所以基本上就是一个查找到 kv 并且置为 deleted 状态的过程。让我们往下看
func (m *Map) Delete(typ *abi.MapType, key unsafe.Pointer) {
// 如果 map nil 或 空,直接返回
if m == nil || m.Used() == 0 {
if err := mapKeyError(typ, key); err != nil {
panic(err) // see issue 23734
}
return
}
// 并发写检查
if m.writing != 0 {
fatal("concurrent map writes")
}
// 计算 hash 并设置写标记
hash := typ.Hasher(key, m.seed)
// Set writing after calling Hasher, since Hasher may panic, in which
// case we have not actually done a write.
m.writing ^= 1 // toggle, see comment on writing
// 小表直接去 group 内删除
if m.dirLen == 0 {
m.deleteSmall(typ, hash, key)
} else {
// 定位 table
idx := m.directoryIndex(hash)
// table 删除
if m.directoryAt(idx).Delete(typ, m, hash, key) {
m.tombstonePossible = true
}
}
// 如果此时删完之后 map 清零了,则重置 hash 种子
if m.used == 0 {
// Reset the hash seed to make it more difficult for attackers
// to repeatedly trigger hash collisions. See
// https://go.dev/issue/25237.
m.seed = uintptr(rand())
}
// 并发写检测
if m.writing == 0 {
fatal("concurrent map writes")
}
// 重置 flag 位
m.writing ^= 1
}
(1)如果 map 为 nil 或空,则直接返回,否则进行并发写检查,计算 hash 值,设置写标记位
if m == nil || m.Used() == 0 {
if err := mapKeyError(typ, key); err != nil {
panic(err) // see issue 23734
}
return
}
// 并发写检查
if m.writing != 0 {
fatal("concurrent map writes")
}
// 计算 hash 并设置写标记
hash := typ.Hasher(key, m.seed)
m.writing ^= 1 // toggle, see comment on writing
(2)接着要进入删除流程,这里也分在小 map 中删除(m.deleteSmall(typ, hash, key))和在普通 map 中删除(m.directoryAt(idx).Delete(typ, m, hash, key))
// 小表直接去 group 内删除
if m.dirLen == 0 {
m.deleteSmall(typ, hash, key)
} else {
// 定位 table
idx := m.directoryIndex(hash)
// table 删除
if m.directoryAt(idx).Delete(typ, m, hash, key) {
m.tombstonePossible = true
}
}
小 map 删除流程:
func (m *Map) deleteSmall(typ *abi.MapType, hash uintptr, key unsafe.Pointer) {
// 获取 group 地址
g := groupReference{
data: m.dirPtr,
}
// 找到组内匹配到的 slot
match := g.ctrls().matchH2(h2(hash))
// 遍历 group 内的
for match != 0 {
i := match.first()
slotKey := g.key(typ, i)
origSlotKey := slotKey
if typ.IndirectKey() {
slotKey = *((*unsafe.Pointer)(slotKey))
}
if typ.Key.Equal(key, slotKey) {
// slot 位使用数 --
m.used--
// 清除 key
if typ.IndirectKey() {
// Clearing the pointer is sufficient.
*(*unsafe.Pointer)(origSlotKey) = nil
} else if typ.Key.Pointers() {
// Only bother clearing if there are pointers.
typedmemclr(typ.Key, slotKey)
}
// 清除 val
slotElem := g.elem(typ, i)
if typ.IndirectElem() {
// Clearing the pointer is sufficient.
*(*unsafe.Pointer)(slotElem) = nil
} else {
// Unlike keys, always clear the elem (even if
// it contains no pointers), as compound
// assignment operations depend on cleared
// deleted values. See
// https://go.dev/issue/25936.
typedmemclr(typ.Elem, slotElem)
}
// We only have 1 group, so it is OK to immediately
// reuse deleted slots.
// 设置控制字节为 Empty
g.ctrls().set(i, ctrlEmpty)
return
}
// 没找到,往下找下一个匹配到的 slot
match = match.removeFirst()
}
}
小 map 的删除流程和查找无异,但是要注意,小 map 中因为只有一个 group,不涉及到探测序列,所以其无需维护 deleted 位,所以删除只需要置为 empty 即可。
普通 map 删除流程:
func (t *table) Delete(typ *abi.MapType, m *Map, hash uintptr, key unsafe.Pointer) bool {
// 初始化探测序列
seq := makeProbeSeq(h1(hash), t.groups.lengthMask)
// h2
h2Hash := h2(hash)
// 按照序列探测
for ; ; seq = seq.next() {
// 定位组
g := t.groups.group(typ, seq.offset)
// 组内匹配的 slot
match := g.ctrls().matchH2(h2Hash)
// 如果有初步匹配的key,则进一步对比 key
for match != 0 {
i := match.first()
slotKey := g.key(typ, i)
origSlotKey := slotKey
if typ.IndirectKey() {
slotKey = *((*unsafe.Pointer)(slotKey))
}
if typ.Key.Equal(key, slotKey) {
// key 值相等,槽位++
t.used--
m.used--
// 移除 kv
if typ.IndirectKey() {
*(*unsafe.Pointer)(origSlotKey) = nil
} else if typ.Key.Pointers() {
typedmemclr(typ.Key, slotKey)
}
slotElem := g.elem(typ, i)
if typ.IndirectElem() {
// Clearing the pointer is sufficient.
*(*unsafe.Pointer)(slotElem) = nil
} else {
typedmemclr(typ.Elem, slotElem)
}
var tombstone bool
// 组内有空位,则将这一位置为 empty 没关系
if g.ctrls().matchEmpty() != 0 {
g.ctrls().set(i, ctrlEmpty)
t.growthLeft++
} else {
// 组内没有空位,则这位必须置为 delete,不然探测序列会被打断
g.ctrls().set(i, ctrlDeleted)
tombstone = true
}
t.checkInvariants(typ, m)
return tombstone
}
match = match.removeFirst()
}
// 看组内是否有 empty 槽,如果有可以直接返回了,代表探测序列终止
match = g.ctrls().matchEmpty()
if match != 0 {
return false
}
}
}
对于普通 map 删除而言,是需要维护 deleted 位的,其本质也和查找类似,先计算出探测序列,然后依据探测序列一组一组的查找,知道查到某个组内包含该 Key 或者这个组内有 Empty 槽。 注意找到元素删除的时候,状态位的设置也是分情况的:
- 如果 key 所在的组内有 empty 状态的 slot,那么这个位置可以直接设置为 empty,因为如果有后续的其他 key 查找经过该组,本身就会因为原先的 empty 状态导致早停,所以这里将这个空槽直接置为 empty 并不会影响经过该组的探测序列的探测。
- 如果 key 所在的组内没有 empty 状态的 slot,那么这里就需要设置为 deleted,从而维护其他探测序列的正常探测。 (3)如果在某个组内没有找到 key,但是发现了 empty,则直接早停返回
// 看组内是否有 empty 槽,如果有可以直接返回了,代表探测序列终止
match = g.ctrls().matchEmpty()
if match != 0 {
return false
}
3.2.5 扩容
扩容是 map 中比较重要的部分,他会涉及到性能问题。在 1.24 后的 go 中,map 的扩容主要分为三种情况:
- 小 map 单 group 扩容为 table
- table 横向扩容(单 table 内的 group 数翻倍)
- table 纵向分裂扩容(单 table 内 group 数已到达上限,分裂成两个 table)
小 map 单 group 扩容为 table
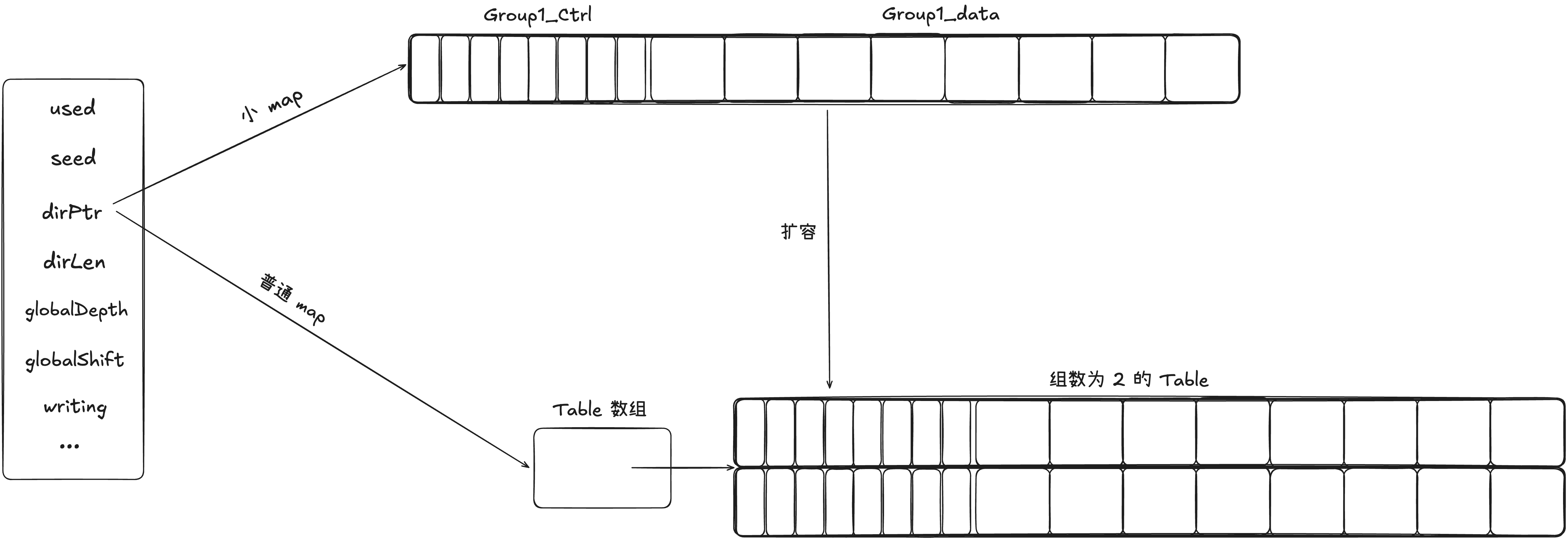
我们知道一开始预估容量小于 8 个 slot 的时候,我们会只给 map 分配一个 group,假设此时 8 个 slot 不够用了,则会让 group 升级为 table。
func (m *Map) growToTable(typ *abi.MapType) {
// 创建一个大小是原来两倍的 table(原来的小表 slot 只有 8)
tab := newTable(typ, 2*abi.MapGroupSlots, 0, 0)
g := groupReference{
data: m.dirPtr,
}
// 从小 map 中迁移旧数据
for i := uintptr(0); i < abi.MapGroupSlots; i++ {
if (g.ctrls().get(i) & ctrlEmpty) == ctrlEmpty {
// 遇到空槽跳过
// Empty
continue
}
// 获取 key
key := g.key(typ, i)
if typ.IndirectKey() {
key = *((*unsafe.Pointer)(key))
}
// 获取值
elem := g.elem(typ, i)
if typ.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// 按照 hash 求出这个 key 的 hash 值
hash := typ.Hasher(key, m.seed)
// 在 table 中找到合适的位置插入元素
tab.uncheckedPutSlot(typ, hash, key, elem)
}
// 创建 dir 数组
directory := make([]*table, 1)
directory[0] = tab
// dirptr 指向 tabel
m.dirPtr = unsafe.Pointer(&directory[0])
m.dirLen = len(directory)
// 此时 Depth 为 0,因为只有一个 Table,不需要任何 bit 位来判断插哪个表
m.globalDepth = 0
m.globalShift = depthToShift(m.globalDepth)
}
(1)创建一个 16 个 slot 的 table,也就是 2 group。
tab := newTable(typ, 2*abi.MapGroupSlots, 0, 0)
(2)迁移原来的 group 中的 kv 对到新 table 中。这里就是组内的遍历和直接插入。
g := groupReference{
data: m.dirPtr,
}
// 从小 map 中迁移旧数据
for i := uintptr(0); i < abi.MapGroupSlots; i++ {
if (g.ctrls().get(i) & ctrlEmpty) == ctrlEmpty {
// 遇到空槽跳过
// Empty
continue
}
// 获取 key
key := g.key(typ, i)
if typ.IndirectKey() {
key = *((*unsafe.Pointer)(key))
}
// 获取值
elem := g.elem(typ, i)
if typ.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// 按照 hash 求出这个 key 的 hash 值
hash := typ.Hasher(key, m.seed)
// 在 table 中找到合适的位置插入元素
tab.uncheckedPutSlot(typ, hash, key, elem)
}
(3)更新 Map 的信息,首先是重新设置 dir 数组,因为原来的小 map 的 dir 指针指向的是一个 group,现在指向一个 table 数组。接着需要设置全局目录的深度,就是在定位一个 table 的时候,需要取 hash 的高多少位。
// 创建 dir 数组
directory := make([]*table, 1)
directory[0] = tab
// dirptr 指向 tabel
m.dirPtr = unsafe.Pointer(&directory[0])
m.dirLen = len(directory)
// 此时 Depth 为 0,因为只有一个 Table,不需要任何 bit 位来判断插哪个表
m.globalDepth = 0
m.globalShift = depthToShift(m.globalDepth)
table 横向扩容
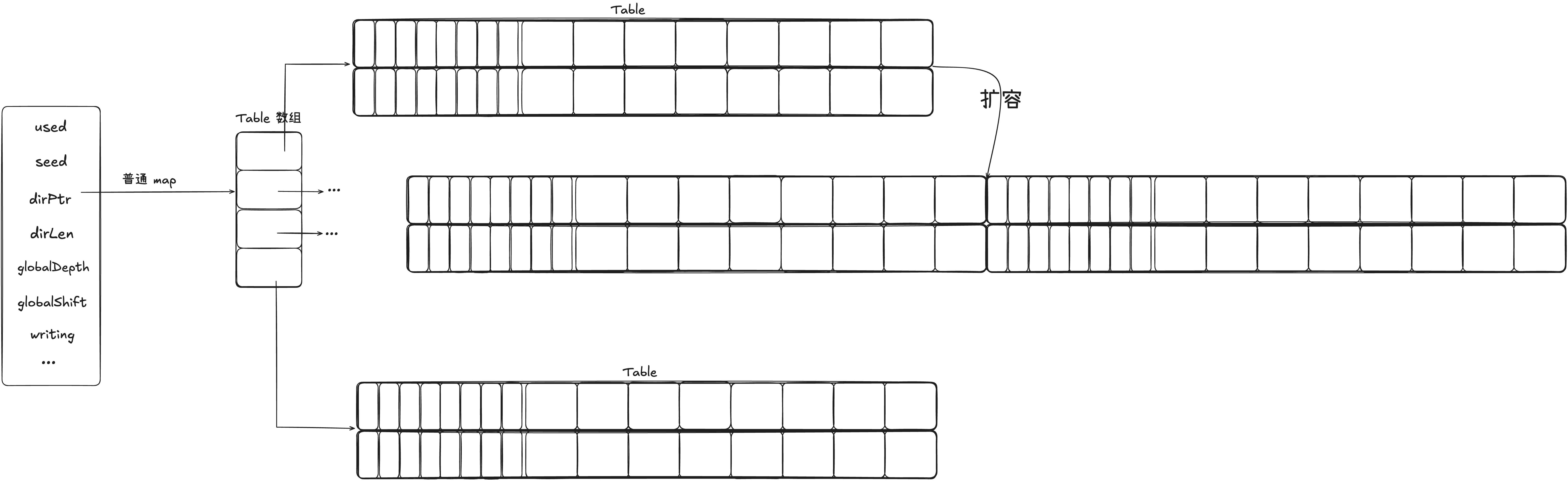
table 的横向扩容是当插入元素到 table 中,此时 table 在插入元素就要超过负载了,但是此时 table 中的组数还没有到达上限,那么此时 table 就会横向的增加 group 数,从而实现扩容。
func (t *table) grow(typ *abi.MapType, m *Map, newCapacity uint16) {
// 此时发生横向的扩容
// 直接分配一个新 table,以代替原有 table
newTable := newTable(typ, uint64(newCapacity), t.index, t.localDepth)
if t.capacity > 0 {
// 遍历原表中的所有 group
for i := uint64(0); i <= t.groups.lengthMask; i++ {
g := t.groups.group(typ, i)
// 遍历 group 中的所有 slot
for j := uintptr(0); j < abi.MapGroupSlots; j++ {
if (g.ctrls().get(j) & ctrlEmpty) == ctrlEmpty {
// Empty or deleted
continue
}
key := g.key(typ, j)
if typ.IndirectKey() {
key = *((*unsafe.Pointer)(key))
}
elem := g.elem(typ, j)
if typ.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
hash := typ.Hasher(key, m.seed)
// rehash 插入
newTable.uncheckedPutSlot(typ, hash, key, elem)
}
}
}
// 更换 table
newTable.checkInvariants(typ, m)
m.replaceTable(newTable)
// 把旧表标记废弃
t.index = -1
}
(1)首先进入横向扩容的条件是,当前的组数,没有超过最大限制的 1/2,因为扩容是翻倍扩容,所以当 2 * t.capacity < 1024 的时候,会进入 grow()
func (t *table) rehash(typ *abi.MapType, m *Map) {
// 新的 table 容量先预设为原来容量的一倍
newCapacity := 2 * t.capacity
// 如果新容量没有超过单表槽数的最大值
if newCapacity <= maxTableCapacity {
// table 横向扩容
t.grow(typ, m, newCapacity)
return
}
// table 纵向分裂扩容
t.split(typ, m)
}
(2)分配一个新的 table,因为需要 SwissTable 需要保障内存的连续性,所以每次扩容都需要重新申请空间。而因为没有增加 table,所以 index 和 localDepth 不会改变。
newTable := newTable(typ, uint64(newCapacity), t.index, t.localDepth)
(3)遍历原 table 中所有 group,将 table 中的所有 kv rehash 到新 table 中,从而实现扩容。
if t.capacity > 0 {
// 遍历原表中的所有 group
for i := uint64(0); i <= t.groups.lengthMask; i++ {
g := t.groups.group(typ, i)
// 遍历 group 中的所有 slot
for j := uintptr(0); j < abi.MapGroupSlots; j++ {
if (g.ctrls().get(j) & ctrlEmpty) == ctrlEmpty {
// Empty or deleted
continue
}
key := g.key(typ, j)
if typ.IndirectKey() {
key = *((*unsafe.Pointer)(key))
}
elem := g.elem(typ, j)
if typ.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
hash := typ.Hasher(key, m.seed)
// rehash 插入
newTable.uncheckedPutSlot(typ, hash, key, elem)
}
}
}
(4)在 Map 中重新设置目录的指针,指向新的 table
// 更换 table
newTable.checkInvariants(typ, m)
m.replaceTable(newTable)
// 把旧表标记废弃
t.index = -1
table 纵向分裂扩容
当 table 中的的组数再扩大就要超出单 table 的限制了,此时就会触发纵向的分裂扩容,table 数量增加,会进而影响到 Map 中更多的字段。
func (t *table) split(typ *abi.MapType, m *Map) {
// 此时发生纵向扩容,也就是说 table 数量会 + 1
// 所以 localDepth + 1
localDepth := t.localDepth
localDepth++
// TODO: is this the best capacity?
// 创建两个 1024 的 table
left := newTable(typ, maxTableCapacity, -1, localDepth)
right := newTable(typ, maxTableCapacity, -1, localDepth)
// Split in half at the localDepth bit from the top.
mask := localDepthMask(localDepth)
// 原 table 中的 kv rehash
for i := uint64(0); i <= t.groups.lengthMask; i++ {
g := t.groups.group(typ, i)
for j := uintptr(0); j < abi.MapGroupSlots; j++ {
if (g.ctrls().get(j) & ctrlEmpty) == ctrlEmpty {
// Empty or deleted
continue
}
key := g.key(typ, j)
if typ.IndirectKey() {
key = *((*unsafe.Pointer)(key))
}
elem := g.elem(typ, j)
if typ.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
hash := typ.Hasher(key, m.seed)
var newTable *table
// 按 localDepth 的那一位决定左/右目标表
if hash&mask == 0 {
newTable = left
} else {
newTable = right
}
newTable.uncheckedPutSlot(typ, hash, key, elem)
}
}
// 在 Map 中注册两个表
m.installTableSplit(t, left, right)
// 原表弃用
t.index = -1
}
(1)首先因为表的拆分,所以 localDepth 会增加,因为 localDepth 代表单表的深度。举个例子可以更好的理解这个字段。
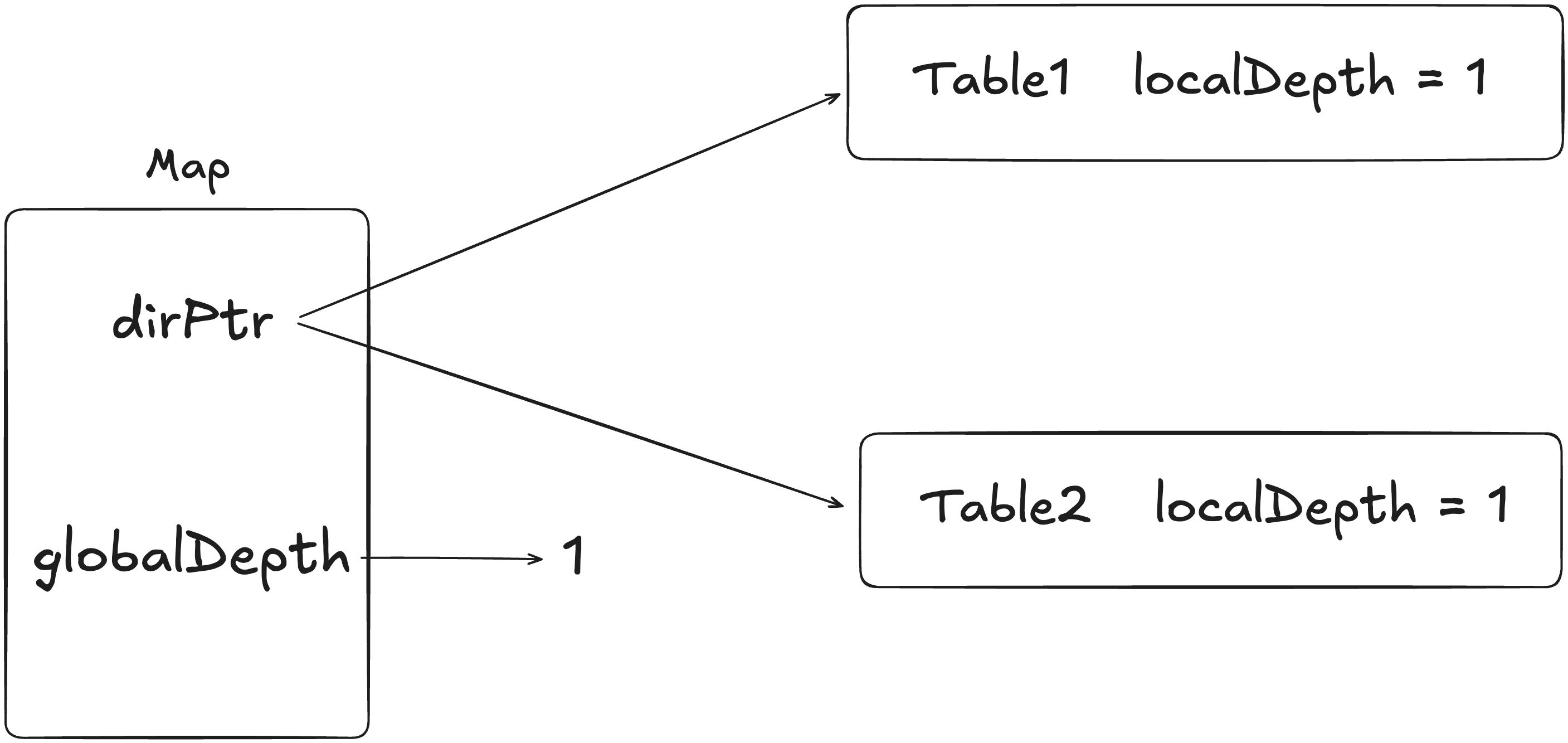
假设当前 map 中是如上情况,globalDepth = 1,则代表需要 hash 值高 1 位就能定位选择那个 table。当高位为 0 时,则定位 table1,否则定位 table2。而 localDepth = 1 代表的则是只需要一位就能确定这个 tabel。因为随着其他 table 的扩容,可能会导致 globalDepth 增加,但是没分裂的table 的 localDepth 不会改变,那对于没分裂的表,只需要 localDepth 就能确定。看下面的例子。 假设现在 Table1 分裂了。
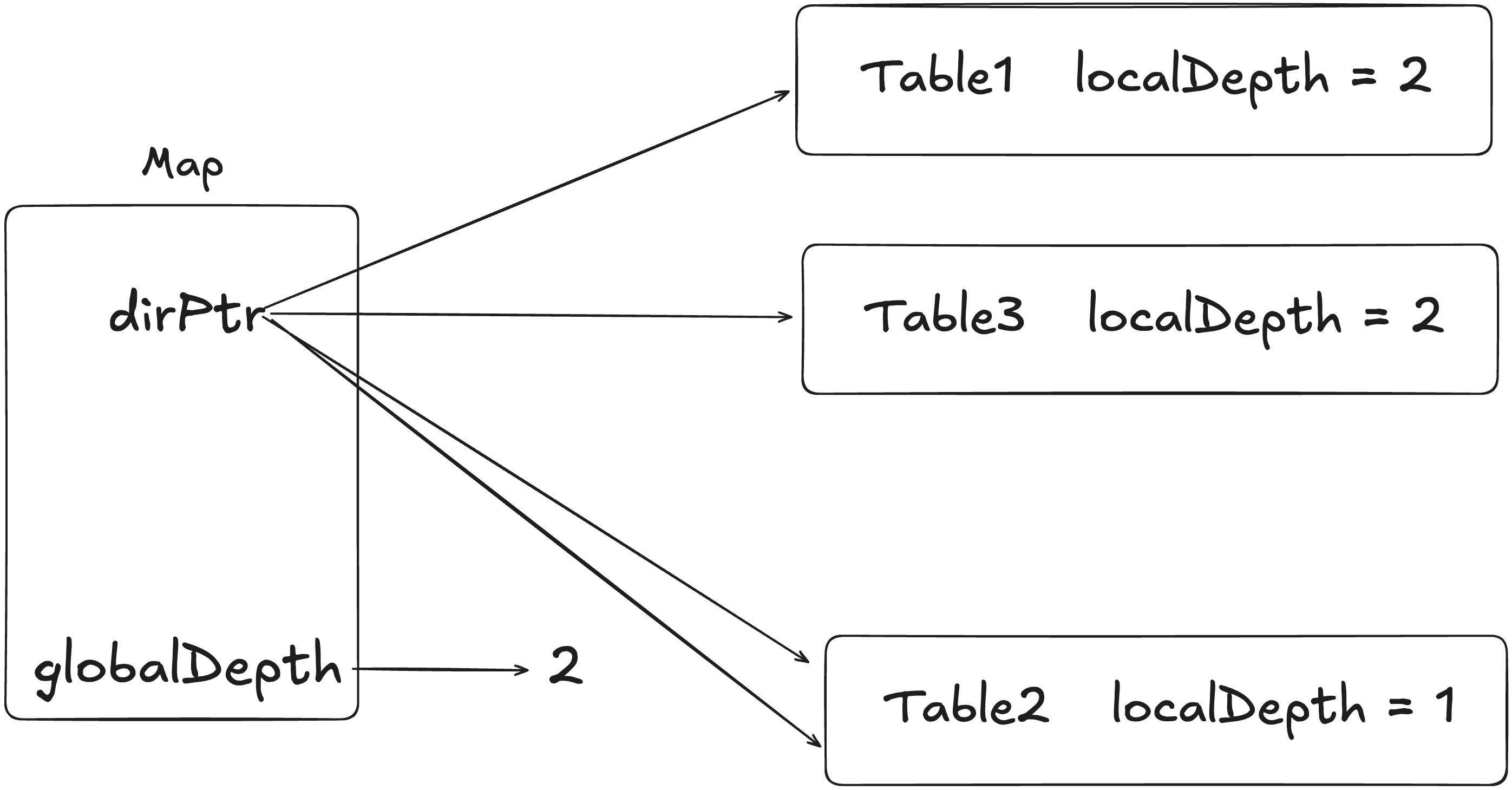 此时在 map 中有 table1 和 table3(table1 分裂出的 table)以及 table2,但是因为目录是成倍扩容的,也就是说 dir 长度为 4。此时目录项 1 和 2 分别指向 tabel1 和 table3,而目录项 3 和 4 都指向 table2,也就是说区分 table1 和 table3 需要高两位。例如00 分去 table1,01 分去tabel3,而 10 和 11 都分去 table2,这就是 localDepth 的意义。实际上就是虽然全局目录会有很多页,但是因为有的 table 不扩容,随着页目录增长,随有很多目录项都指向同一个 table,所以这些目录项所代表的低位是没有参考价值的,只需要高 localDepth 位就能确定其所在的 table。
(2)拆分 table,创建两个最大的 table,分别作为拆分后的两个 table。
此时在 map 中有 table1 和 table3(table1 分裂出的 table)以及 table2,但是因为目录是成倍扩容的,也就是说 dir 长度为 4。此时目录项 1 和 2 分别指向 tabel1 和 table3,而目录项 3 和 4 都指向 table2,也就是说区分 table1 和 table3 需要高两位。例如00 分去 table1,01 分去tabel3,而 10 和 11 都分去 table2,这就是 localDepth 的意义。实际上就是虽然全局目录会有很多页,但是因为有的 table 不扩容,随着页目录增长,随有很多目录项都指向同一个 table,所以这些目录项所代表的低位是没有参考价值的,只需要高 localDepth 位就能确定其所在的 table。
(2)拆分 table,创建两个最大的 table,分别作为拆分后的两个 table。
left := newTable(typ, maxTableCapacity, -1, localDepth)
right := newTable(typ, maxTableCapacity, -1, localDepth)
(3)rehash 原来表中的数据到新的两个表中,用高 localDepth 的最低位判断分去哪个 table 中。
mask := localDepthMask(localDepth)
for i := uint64(0); i <= t.groups.lengthMask; i++ {
g := t.groups.group(typ, i)
for j := uintptr(0); j < abi.MapGroupSlots; j++ {
if (g.ctrls().get(j) & ctrlEmpty) == ctrlEmpty {
// Empty or deleted
continue
}
key := g.key(typ, j)
if typ.IndirectKey() {
key = *((*unsafe.Pointer)(key))
}
elem := g.elem(typ, j)
if typ.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
hash := typ.Hasher(key, m.seed)
var newTable *table
// 按 localDepth 的那一位决定左/右目标表
if hash&mask == 0 {
newTable = left
} else {
newTable = right
}
newTable.uncheckedPutSlot(typ, hash, key, elem)
}
}
(4)在 Map 中注册这两个 table,并且弃用原表。因为 table 增加,所以 Map 中的表目录也扩大,表目录指针的指向也要改变。
// 在 Map 中注册两个表
m.installTableSplit(t, left, right)
// 原表弃用
t.index = -1
func (m *Map) installTableSplit(old, left, right *table) {
// 目录需要扩充
if old.localDepth == m.globalDepth {
// 如果全局的表深度和原来的表一致,那就代表深度不够了,需要重新增加
newDir := make([]*table, m.dirLen*2)
for i := range m.dirLen {
t := m.directoryAt(uintptr(i))
// 每个旧入口复制成两个相邻的新入口
newDir[2*i] = t
newDir[2*i+1] = t
// t 可能本来就被多个目录项引用,更新 table 的 idx
if t.index == i {
t.index = 2 * i
}
}
// 全局深度增加
m.globalDepth++
m.globalShift--
//m.directory = newDir
m.dirPtr = unsafe.Pointer(&newDir[0])
m.dirLen = len(newDir)
}
// 不需要扩充目录
// left 的 idx 是旧表的 idx
left.index = old.index
m.replaceTable(left)
// 同理
entries := 1 << (m.globalDepth - left.localDepth)
right.index = left.index + entries
m.replaceTable(right)
}
首先会判断当前这个表的 localDepth 有没有超过 Map 的globalDepth,如果超过,就代表 dir 不够用了,需要重新分配空间,并且重新分配指针指向;否则不需要扩容dir。例如上面那个例子,假设此时 table2 要继续split,那么并不需要扩容 dir,只需要将 table2 所占用的第一个目录指针指向分裂后的第一个新表,第二个指针指向分裂后的第二个新表即可。
3.2.6 迭代(TODO)
迭代感觉 go 团队都还没想好怎么做,目前只是初始版本啊…….
4 彩蛋
4.1 这里为什么 go 没有采用一个组 16 个槽,一步提高对比的效率呢?
我认为 go 是为了移植性和初步实验,底层采用的应该不是 SIMD 并行比对的,而是使用了另一种并行方案——寄存器内并行,我们现在的平台基本上都是 64 位平台,也就是说寄存器是 64 位,这样的情况下,go 的这套代码不需要指令支持,只需要寄存器内并行即可计算,当然后续可能会采用 SIMD 提高效率,因为 go 现在的 map 代码中存在大量的 TODO;而且也有人发现,在某些场景下,SwissTable 的效率远不如原来的拉链法,所以慢慢等看 go 的团队如何做抉择吧。